Good morning. I am having continuously increasing non-heap memory usage and metaspace usage, and I am at a loss for how to resolve it. This usage is resulting in deeply disruptive, network-severing server meltdowns. I could use some suggestions – my mind is very open to ideas on how to address this. I can’t tell if this is a Lucee bug (seems unlikely, but possible), an issue with my server setup (certainly possible) or, even, if I am approaching my Lucee .cfm code in a way that’s causing problems (also possible).
Server Setup Background
I’ve been struggling for about two months with a shift to a new server setup for my Lucee application. My original server was Ubuntu 18 with Lucee 5.4.3.16 and MySQL 5.7, NGINX reverse proxy, Java version 11, 1 vCPU, 2 GB RAM. For several years it was a remarkably stable operation. With Ubuntu 18 reaching EOL, I needed to move to a new server.
This was a challenge on its own, but I appreciate all of the people who have been patient with me as I attempt to get it set up. I’ve made five different attempts at a new server.
I’ve done manual builds on about four different new AWS Lightsail instances. Based on feedback from this thread as well as lots of patient assistance from Ortus members here and here, I set up my current server (fifth attempt) on CommandBox.
The current server is running Ubuntu 20.04, Lucee 5.4.4.38 served through CommandBox (with embedded server enabled), NGINX as a reverse proxy, Java version 11, and MySQL 8.0 (this is an upgrade, too, from 5.7) as a database, with 2 vCPU (an increase!) and 2 GB RAM.
The server starts and performs like normal (quite well, really) until it reaches the thermonuclear memory meltdown at which point the only recovery is through forcing a 10-minute shutdown through the AWS Lightsail dashboard.
My Application Background
My Lucee web application is a personal website that processes and displays weather data, some webcam images and other small things. It is a hobby project. It receives almost no traffic. It has about 20-25 scheduled tasks to manage the data and image processing. There are many, many interactions with MySQL.
Critically: the code has not changed. The code, which was stable (multi-month, no-drama uptime, years of successful operation), remains the same from the old server to the new.
I also copied the exact same lucee server/web configuration from the old, stable instance to the new one, setting-by-setting match.
When moving to the new server, the server launches and operates just like normal until reaches a point – randomly and without pattern or unique triggers (any random page load or shell operation will trigger this) – where it becomes extremely unresponsive. It halts all network activity, monit is unable to function to restart programs, it just enters a state of panic and hangs. I have to use the AWS Lightsail console to reboot, which takes about 10 minutes due to the unresponsiveness of the server.
My code approach
As a hobbyist, I’ve learned CFML in bits and pieces over 20 years. The pages are mostly written in tag-based CFML code (I know that annoys people, but that’s how I learned.)
I’ve never had to worry about “scope declaration” strategy or caching, so haven’t set any of that up. This is not the world’s most complicated set-up, and, again, the server was performing admirably – with room to spare! – for several years.
I am sure that an expert/pro could view my CFML code as “sloppy,” which is fine. I’m open to improving it and adopting better best practices, but, again, in the past, the server did not have these “increasing memory until crash” issues – nothing even close to it.
None of my pages are unusually long-running. I have no long-running MySQL queries. The workload of the application did not change between servers. No additional traffic is hitting it. There are a few hundred .cfm pages, no one page is more problematic than others.
Memory Issues – FusionReactor and JVM Arguments
(Never before have I had to worry about the intricacies of Java’s memory management, either in terminology or in practice. So if I say something “wrong” here, it’s because I’m ignorant.)
As described earlier, the server is reaching (what I think are) “Out of Memory” (OOM) events. I’m not getting the typical Lucee “yellow box” errors about this, I’m getting kern.log events invoking oom-killer (which, btw, doesn’t work, the server will hang unresponsive for eternity unless rebooted.) All network traffic halts and the server seizes up entirely – monit can’t even close things.
Both old and new servers have these Java options (from server.json, also note that the server exhibits the same behavior whether these JVM arguments are enabled or not)):
"JVM":{
"heapSize":"512",
"properties":{
"java.awt.headless":"true"
},
"args":[
"-XX:+UseConcMarkSweepGC"
]
},
I’ve installed FusionReactor trials to see what I can find out about memory space, based on the advice I’ve seen throughout the internet and from people like @carehart.
With a lot of of influence from @carehart’s response here, along with other threads he and others have written, I’ve used the tools within FusionReactor to gain insight into Memory usage within Lucee.
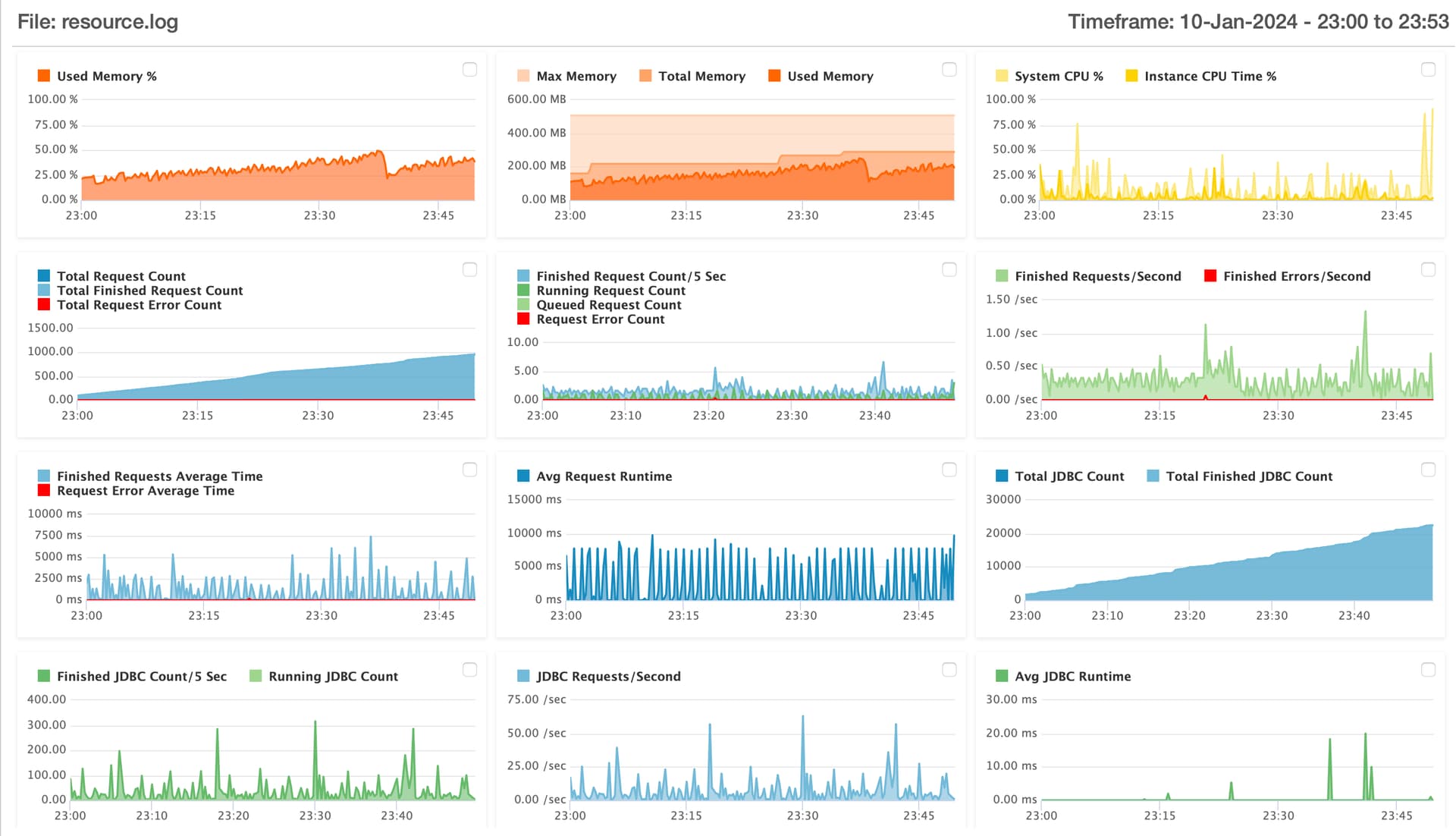
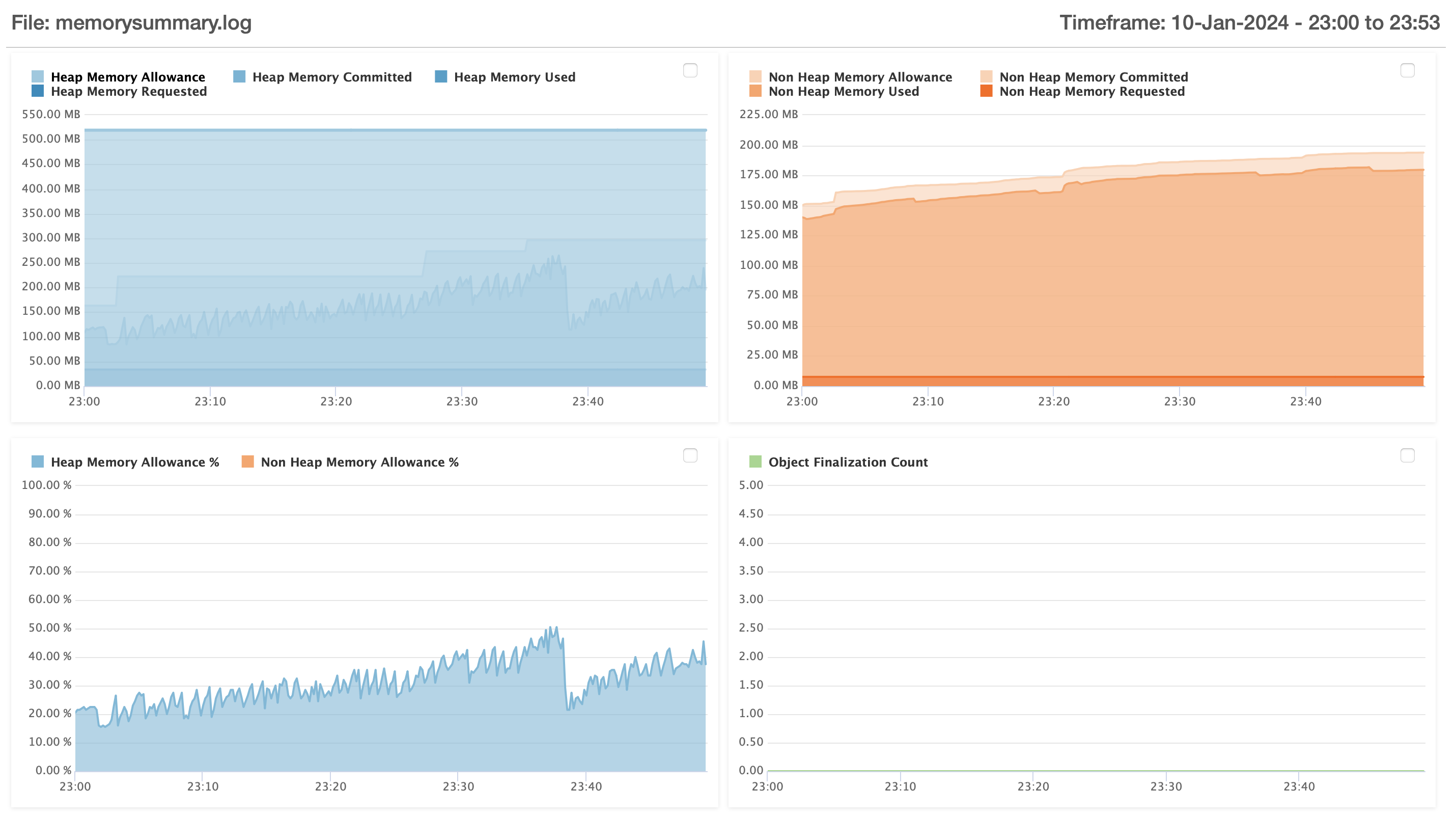
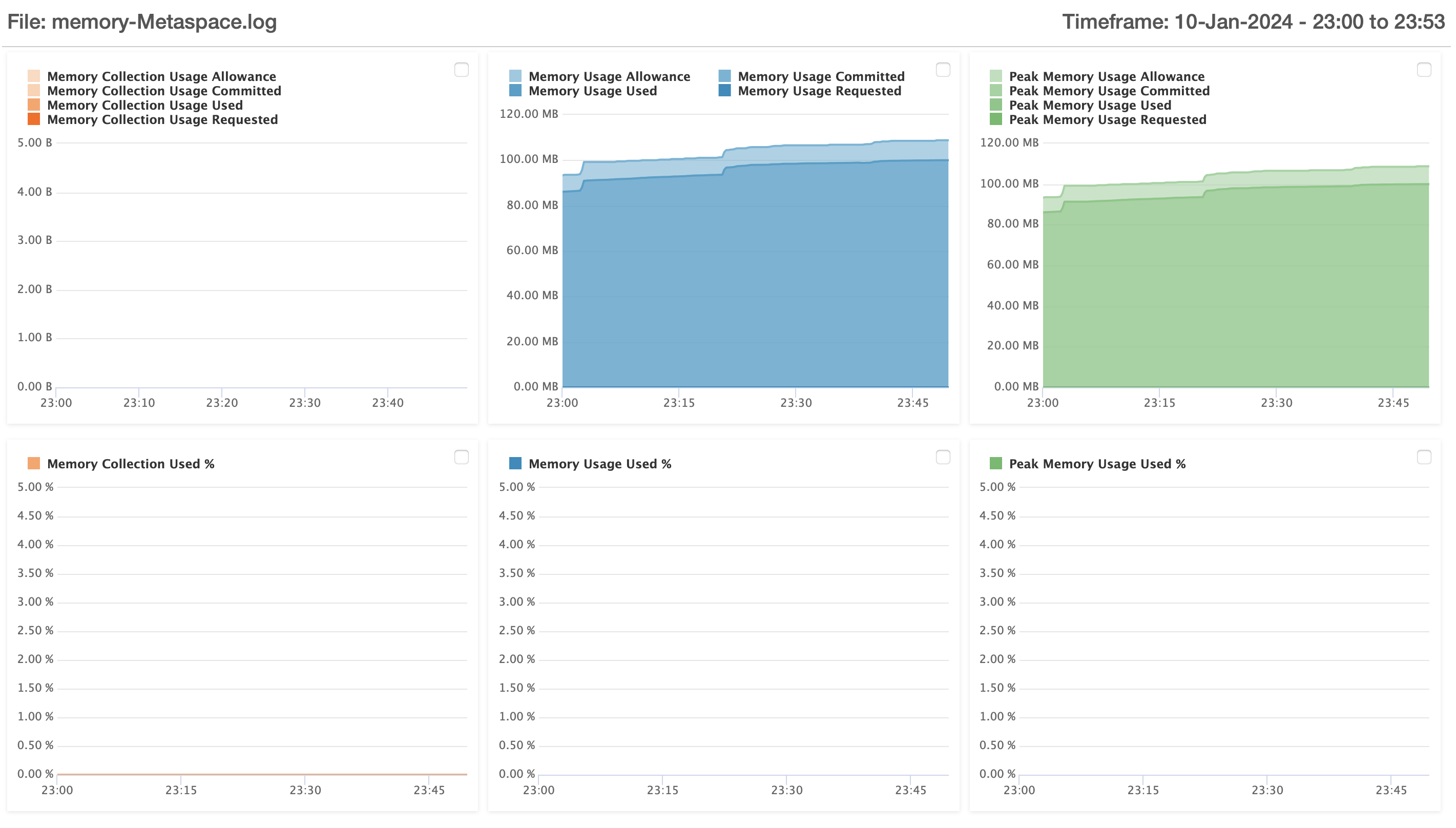
Here are some (hopefully) helpful illustrations from FusionReactor from today with about an hour of time under the server’s belt from its last restart.
Memory
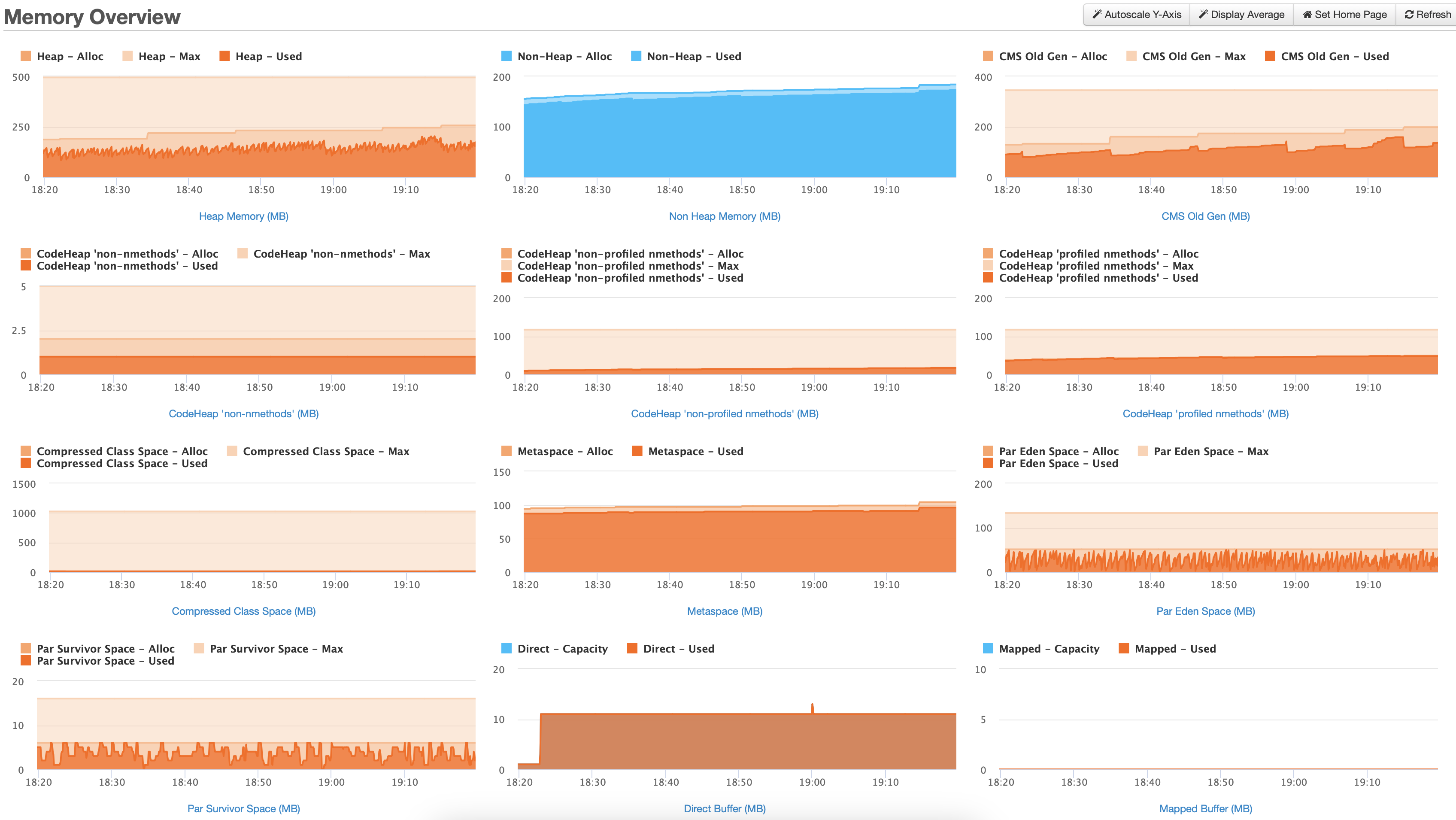
As you can see, we are in a death spiral. You can see the ever-increasing non heap memory usage, never, ever, ever to go down, literally ever, it will not reduce. Ever.
Class Loading
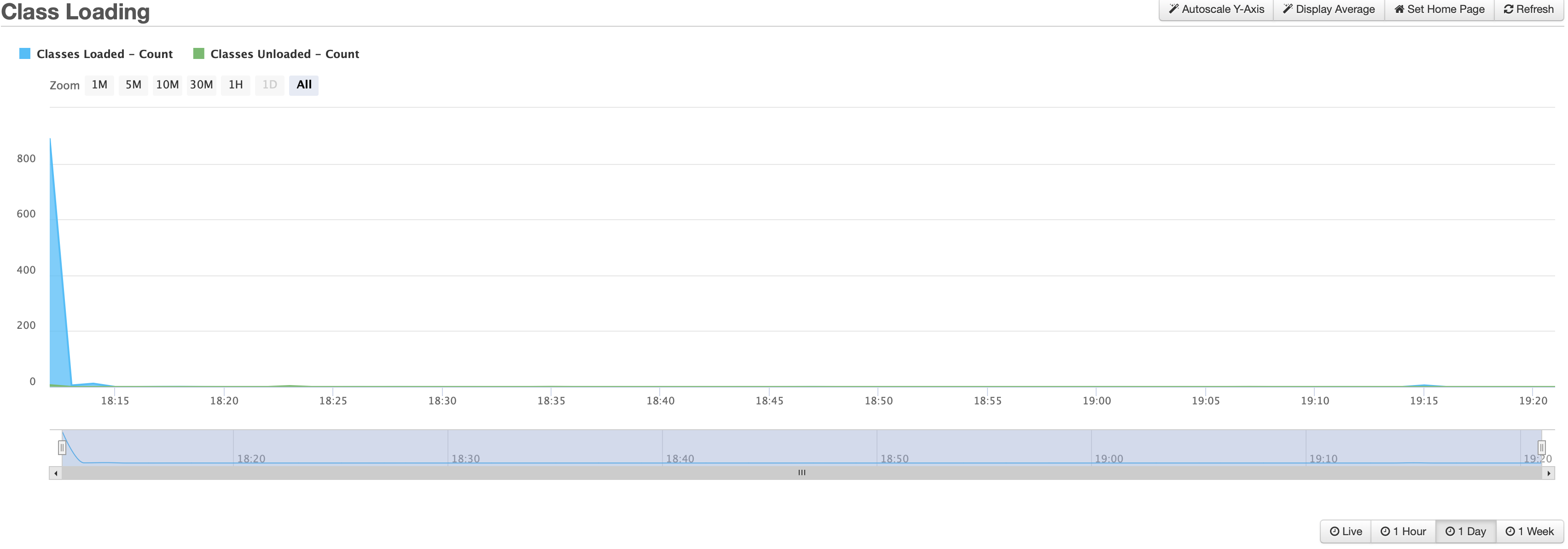
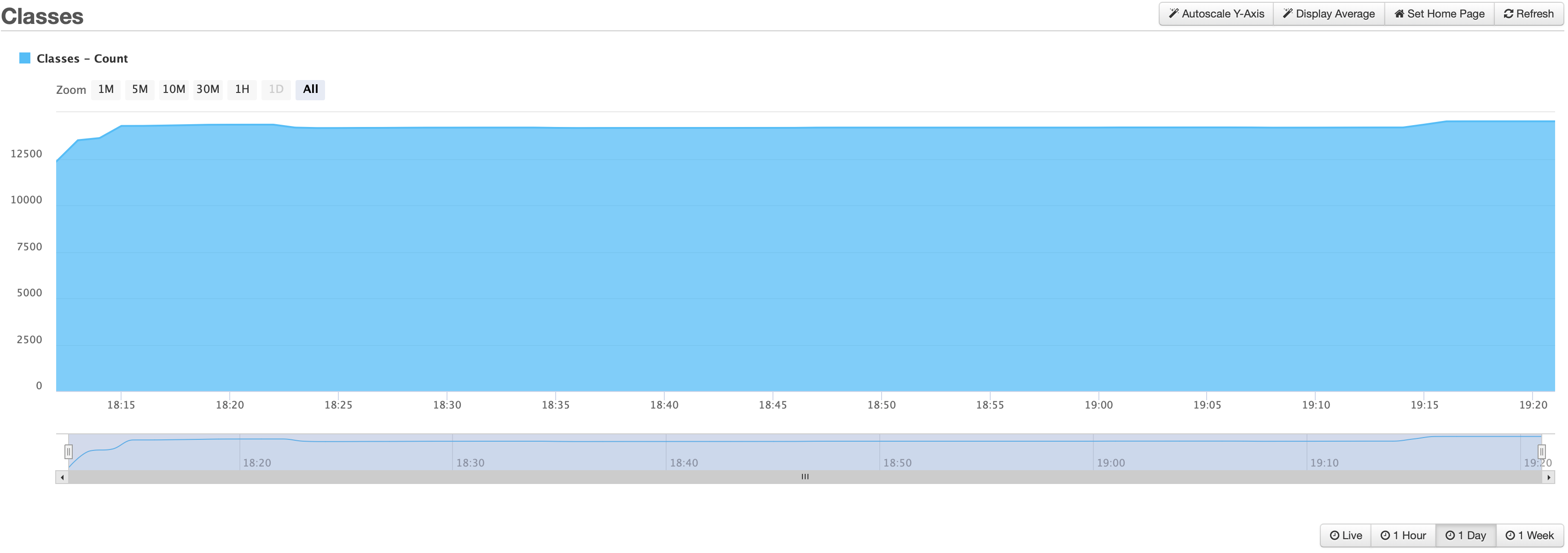
Here we see class loading and number of classes, which spike at launch and then rain mostly steady, usually increasing very slowly throughout the server’s short life on this earth. Some classes get unloaded, but just a handful, while hundreds more classes load regularly.
I have run heap dumps of the Lucee instance and used the Eclipse Memory Analyzer Tool to compare them and search for leaks – none are identified with this tool.
Past Lucee bugs
I have also, of course, looked at threads like this, and this, as well as the associated LDEV things here and here, which describe ever-increasing Memory heap usage and attempts to fix them. I haven’t seen movement in those threads for months, so … there you go, I guess.
Things I can not be sure of
- The move from MySQL 5.7 to 8.0
This I can not be sure of – whether there are changes to the Lucee interactions with the Datasources or if MySQL 8.0, itself, has some kind of issue. But … given the popularity of MySQL, I’d think this is unlikely. - Ubuntu 20.04 vs 18.04
I mean, I guess it’s possible that this introduces some weird new memory management issues, but I’ve not seen anything clear on this in searching.
Things I have tried
- Multiple server versions. I’ve tried Lucee 5.4.3.16 all the way through Lucee 6 – all have the same behavior.
- Adjusting MySQL buffer pools. No change to Lucee’s non-heap behavior.
- Pressing “Garbage Collection” in FusionReactor – results in no change to non-heap memory or loaded classes.
- Examining the heap – not seeing any specific pages or operations that are being referenced, other than
byte[],java.lang.string,java.util.HashMap$Node– nothing notable in these. - Pressing “Clear Page Pool Path” in server administrator – no change to memory usage or classes loaded.
- Plenty of other stuff but this list could go on by hundreds of items.
What now?
This is the most comprehensive forum post I’ve ever written, probably, but I hope it can capture where I’m at, why I’m at a loss for explanation and how I’m unsure of where to proceed.
If anybody has any tips or ideas on how I can best approach investigating and fixing this, I’d be grateful. I will attempt to not be “defensive” of my code, but, I will again note that the code itself has literally gone totally unchanged and was totally problem-free before this server move. But I also recognize that some variable in this move could have triggered something in my code to make it basically completely problematic. Any diagnostic code to identify this would be useful.
And, I want to also add, I am a hobbyist at this. Much of the terminology and knowledge is very challenging for me, and I do not have resources to “hire a professional” or “call in a pro” or something like that. I also don’t want to move to a hosting service, as I need file system control for the image processing and other items.
TL;DR: My Lucee application worked flawlessly for years and now it is fundamentally unstable and unreliable. I could use help learning why and how to fix it.