Putting aside all the criticisms, I’d like to focus on your last note and your observation that all attempts to get things going have eventually failed to run well (out of memory errors), even when (it seems) things may have worked at first. (Or do I have that wrong?)
Thinking back on your last good, working variant, isn’t it possible that Tomcat (or whatever you’d deployed Lucee on) had been changed by you (even perhaps several years ago) to have a higher level Java heap/max memory pool size?
Maybe all that is wrong is that every new variant you’ve implemented had had the default (which is small). Might you still have ANY copy anywhere (even if just a backup, not running) of how things were configured when things worked?
If not, let’s consider the contention that “nothing has changed” about your code, since things last worked, such that you contend it MUST be something new and different in Lucee (or some component it uses, like mod_cfml). Again, for now, I want to put aside consideration of your many other disappointments with the current state of Lucee and its docs.
Might it just be that your new implementations are suffering from excessive traffic that might be brought on by hackers, thieves, and other miscreants, on top of search engine crawlers of many shades? Perhaps the former have picked up in volume coincidentally during this move to a new platform that you’ve been trying.
It’s not ludicrous to consider: I’ve helped many folks in recent weeks who found a tremendous increase in automated traffic which we found was due to requests all reflecting new user agent headers they’d never seen before. (And whether using Lucee or CF, and whether fronted by Apache, IIS, or otherwise, there are solutions to block such unwanted user agents. And it’s worked remarkably well, though some might think the bad guys would just change user agents. Some just can’t be bothered.)
Now, I realize you may say this is more of that mumbo jumbo server talk that you’ve never had to understand. Or you may grok it and want to contend it can’t be this because of reason x, y, or z.
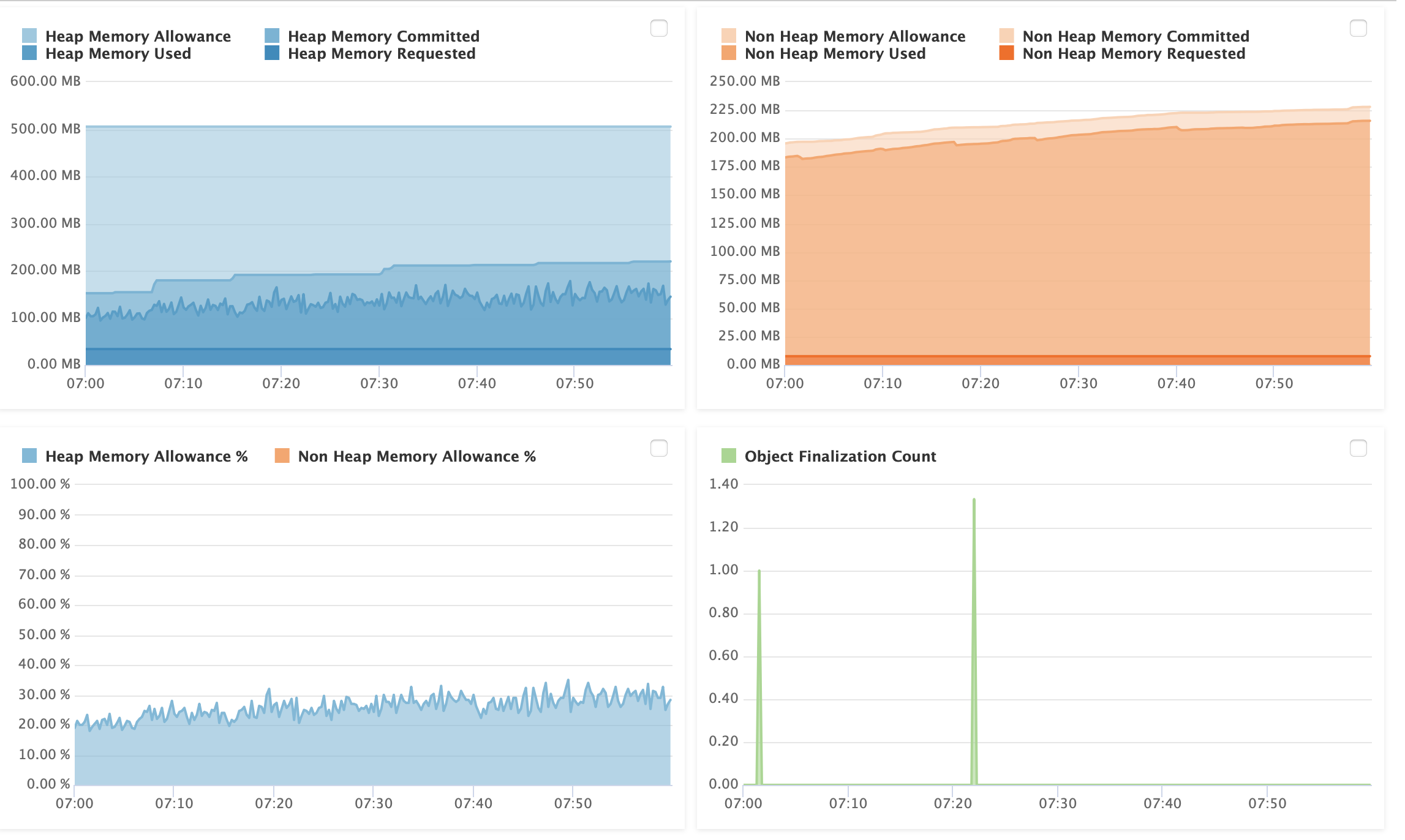
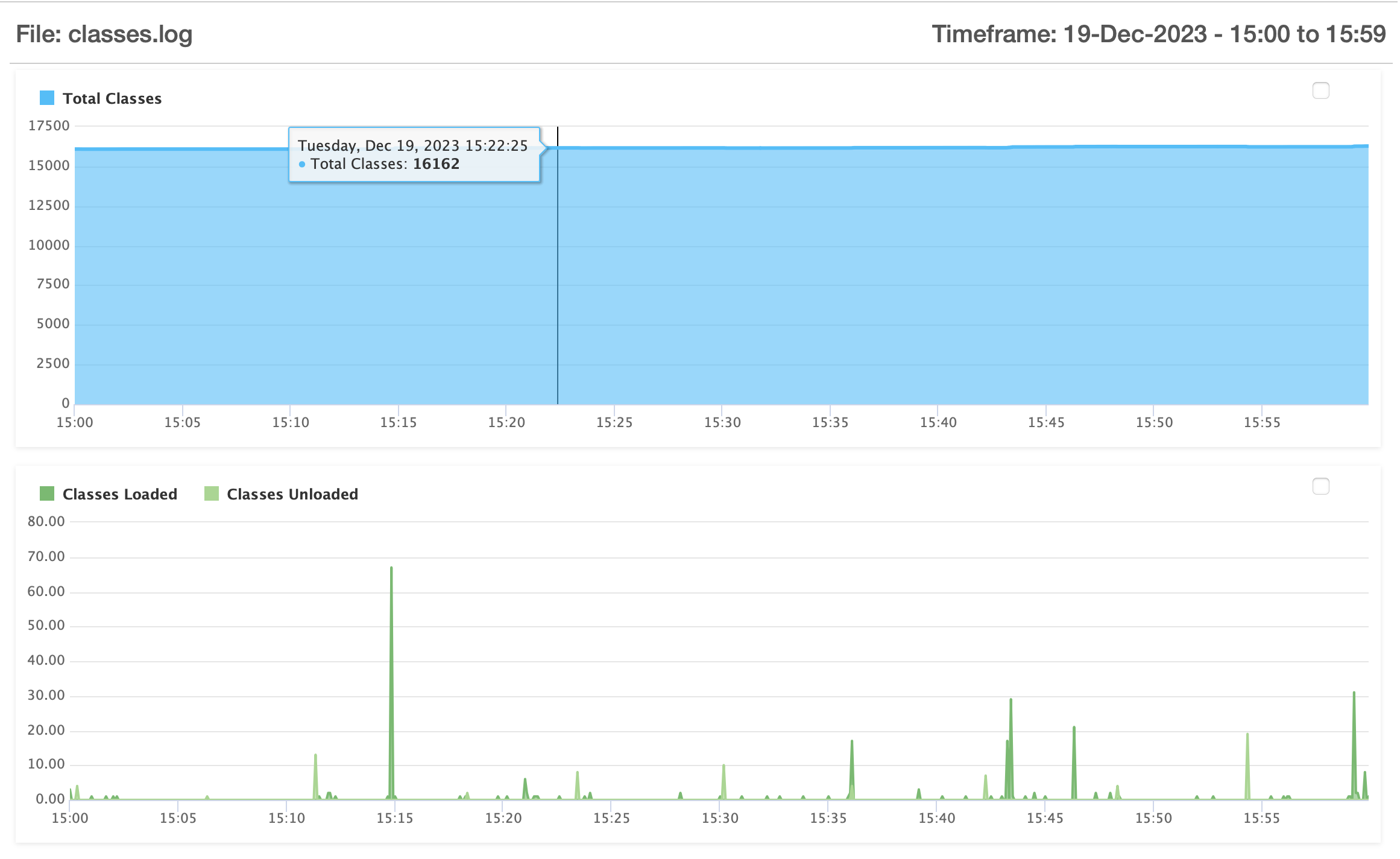
But I will say that since you have fusionreactor in place, we can find with 100% clarity where the problem is: whether it’s about requests piling up, or high rates if requests, or heap (any of its parts) running out, or Gc’s being at issue, and on and on.
I get it, though: you’ve not been able to make heads or tails of it as you’ve assessed it. I totally understand that. In fact I created a 4-part intro video series a few years ago walking through how to use it to troubleshoot such problems. Yes, it will take a few hours of your time. If you’re really wanting to know how to leverage it for such challenges (whether with lucee or cf or other things it can monitor), it will get you on a very good footing. Just Google : arehart fusionreactor playlist, or see this url:
Or as others have mentioned, folks who prefer direct assistance can get it from folks like myself. I realize many people who use Lucee for free are not interested in paying for help. That’s where the community and docs usually help folks otherwise, or grit and determination win out when those fail them. Yours is a sad tale indeed, and you’ve raised some points worth considering, but you can’t push rope. Time will tell if anything is done or if you’ll win many folks to your perspective. As you said, some folks are satisfied with things as they are, or feel anyone who feels otherwise can “do something about it”. That’s a hornet’s nest you’re poking.
That’s why I’ve chosen here to focus on the more technical aspects of your server troubles, and about helping you better leverage fr if you care to. For now, I’ll leave it at that (hoping it helps you, without getting stung myself).