Edited-this is a bug or choice in lucee. See Bens’s comparison to ACF
I’m trying to implement the PUT/GET patterns for long-running processes and Futures seemed like the perfect solution. But after doing all of the refactoring to use runAsync I found that it never executes my code and I have no insight into why not. Nothing is logged in lucee and I suspect the problem is that runAsync runs in an entirely isolated space separate from the calling application. That’s not documented or hinted at anywhere, so if its true that’s a huge oversight.
Is runAsync the right solution for this pattern and I just have a too-tightly coupled application? Are coldbox’s async pipelines/futures different in this regard? Their docs say you can load the application context but that you shouldn’t, is that because the whole application loads inside the thread?
The map/reduce/each/etc functions are perfect in structure for what I’m trying to do, but they have to finish before the request completes, defeating the purpose of put/get. Any help is appreciated.
To be clear, are you saying that you’re making PUT/GEThttp calls from a long running task? And you wanted to move those http calls into a runAsync() callback?
I’ve only played around a bit with runAsync() a few years ago and I did not love the developer experience. Have you considered just running these Put/Get calls inside a CFThread (which can run beyond the current page request, if you set the setting requestTimeout higher.
Another thought is to put relevant data in the database; and then process that data using a scheduled tasks so that it’s still in the “application context”, but isn’t tied at all to the current request.
I know this is just generic feedback because I don’t fully understand the issue you are encountering.
The pattern refers to a PUT http call that initiates a long-running process, where the request completes immediately with a 202 response and a URL to GET/poll for process completion. So my PUT call runs some code that takes awhile, which I have tried to encapsulate in runAsync and then my GET call checks if the Future has completed.
cfthread could accomplish something similar but has high friction on error handling and introspection. Using the pub/sub pattern you describe with a scheduled task is a little too async for me, though I use it for other things.
The issue comes down to this: inside runAsync I try to access cached structures and methods inside the application context and they aren’t there, leading me to believe that runAsync creates its own application context.
Ah, ok, I better understand what you’re saying now. So, then I assume that your GET request is checking some application-scoped variable that something inside your runAsync() call is setting when it’s done? Maybe if we understand more about what the GET call is doing, we can work backwards from there.
As far as I remember, the runAsync() callback should be able to access the application context. But, I’ll have to try running some tests to confirm.
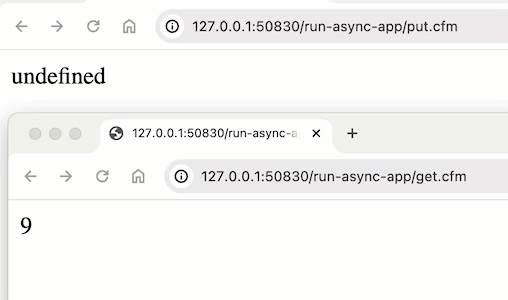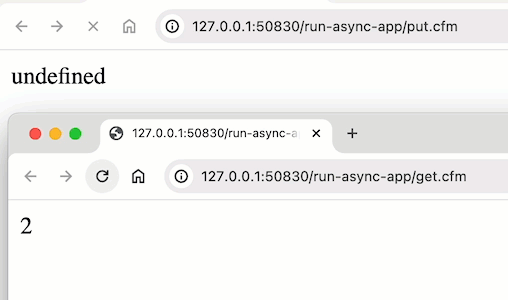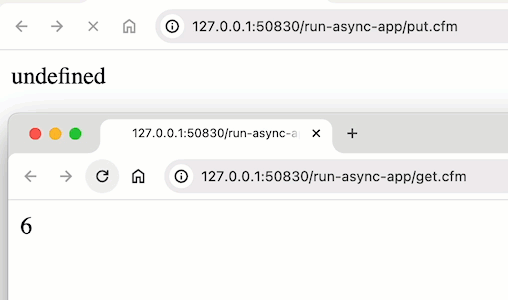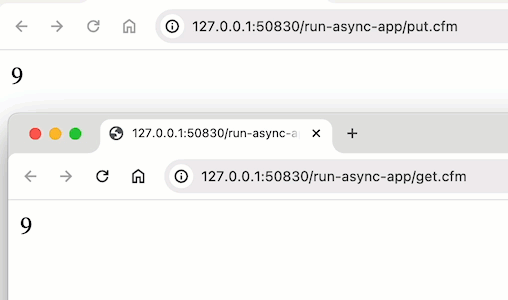
@jonathan.haglund ok, this seems to be something strange in Lucee CFML. Maybe a bug? Maybe something they chose. But, when I run the same code in Adobe ColdFusion, I get the “expected” output:
^^^ that’s me referencing application.counter across two pages; and updating it within the runAsync() callback.
Its my lucky day. I save the future itself to the application context so that I can call isDone() on it for finality. Within the runAsync call’s error() I try to capture the error and context but that also fails because again no access to application, which means no logger.
That’s fantastic. I switched to Coldbox’s async implementation so I could get my feature delivered, but now I’d like to re-ask my original question in that context: when is the built-in runAsync() preferable over the *box async manager? I already understand the additional features of the *box one, so is it a preference thing? Are there overhead differences? Not comparable? For code that needs to not block the main thread but which needs to finish eventually and either return a result or log an error, is there a clear answer?
I believe they are both using the Java Future concept under the hood. So, I think it’s more about the developer ergonomic choices of each implementation. I don’t know much about ColdBox; but, they almost certainly made their version to “smooth out” the rough edges of ColdFusion’s implementation. And, also (I’m guessing) to add more functionality around scheduling and handling collections of futures.
My gut feeling is that the notion of runAsync() was intended to create parallelized work that could still be completed and consumed in the current request (and used to generate the page response). At least on the Adobe ColdFusion side, this is why (from what I vaguely remember) error handling essentially creates a block-and-wait workflow - because they didn’t want stuff to just disappear into the background.
So, I think if you had a lot of DB calls to make in order to get the data for the current request, running them in parallel using something like runAsync() might make sense; and then, collating the responses into the current page response.
But, if you just want a “fire and forget” logic branch, I am not sure that was the intention. I mean, to be clear, this is 100% just my opinion. But, for fire and forget, I would be more inclined to use cfthread or a scheduled task (with some persisted data storage).
I’m a little late to the party but I had to chime in with this.
In my attempt to leverage the runAsync() functionality in Lucee I consistently found that parallel execution was not happening in the way described at the ACF site: RunAsync at Adobe. Specifically the Example 5 section.
After simplifying the example a bit I created the following GIST at TryCF.com.
The code appears to run parallel as expected in ACF but serial in Lucee.
In the code, I create 3 futures that sleep for between 1 & 10 seconds. In ACF the total time of the page execution is pretty close to longest running future; which I expect. However, when the code executes in Lucee, the total time is roughly the sum of the future running times.
Is this a bug or a feature that Lucee doesn’t support?