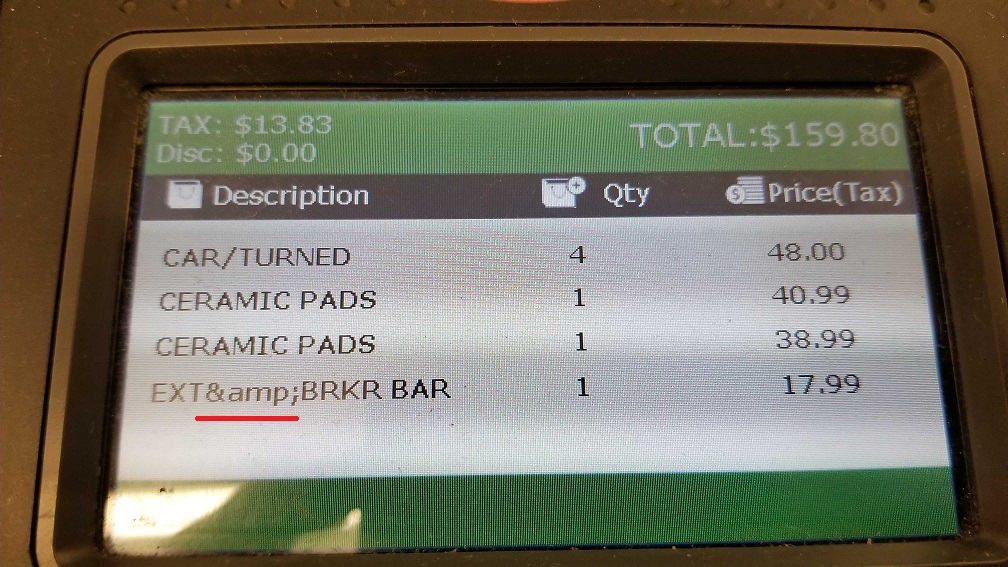
I highly recommend against doing this. It’s bad form and sloppy IMO. Values should be encoded at the time of use based on the medium they’re being injected into. Here is a perfect example of this sort of preemptive encoding gone wrong which I found at my local auto parts store:
You can see some clever developer decided to just encode everything the DB directly, which led to incorrect output on their point of sale devices which don’t use HTML! There are many types of encoding-- for URLs, HTML, Javascript, XML, XML attributes, etc and each one has different rules. Don’t ruin your data when it comes in by making guessing about how you’ll use it later.
And secondly, who are you to say is valid data? If I legally changed my name to be Brad <br> Wood and all legal documents pertaining to my name contained exactly that text, then when I type my name into your form fields, it’s not your job to guess what about that string is valid. It’s your job to store exactly what I input, and when you go to output it, you encode it properly based on the location it’s being output.
<h1>#encodeForHTML( customer_name )#</h1>
or
theURL = "http://site.com/index.cfm?customer_name=#encodeForURL( customer_name )#";
or
<script language="javascript">
var customer_name = '#encodeForJavascript( customer_name )#';
alert( customer_name );
</script>
You want to keep the user’s data in-tact and only encode it when necessary based on the output medium.
Canonicalizing is another place where data can actually be lost when you don’t expect it to. Take the following string for example
%2525
Now, let’s say you need to include it in a URL and still maintain all of its data. URL encoding it will correctly give you this:
%252525
which can be successfully decoded back to the original string. But if we encode it with canonicalization enabled, we get this!
%25
which, when decoded again, gives you only
%
which isn’t at all what the original input was! So by blindly canonicalizing our data, we can actually lose important data.
And finally, depending on your application, you may be expecting HTML meta characters to be submitted if you have any sort of a CMS or comment system that allows users to submit HTML markup. CF’s “script project” feature already gives people fits in this case by replacing some tags in their CMS’s with invalidtag. The correct solution here is using a library like AntiSamy to clean out specific unwanted markup only on the form fields where it makes sense.
If you’re looking for some sort of global protection to help lazy devs who forget about encoding, I would recommend looking into the encodeFor attribute of the CFOutput tag.
Then all variable interpolation inside of that tag will automatically be encoded
<cfoutput encodeFor="html" >
#customer_name#
</cfoutput>
You can even set the default value for this attribute for your entire app in your Application.cfc with something like this:
this.tag.output.encodeFor='html';
Just keep in mind there doesn’t appear to be a method in Lucee to override the attribute back to the default for certain tags.