Had another go at upgrading the troublesome server to the current stable release 5.3.4.47 and it seems the issue is still there.
But we have identified the specific area of the application which seems to be triggering it.
As before, the patch was applied on a Sunday and there were no issues until Monday morning when we started to see memory use rising and garbage collection recovering less and less.
We noticed though that jumps in memory were happening on the hour, which led our attention to a fairly complex scheduled task which, as it happens, runs on the hour during business hours only.
So we disabled the task temporarily and sure enough, memory usage stabilized around its current level. You can see all of this in the folowing FR memory graph:
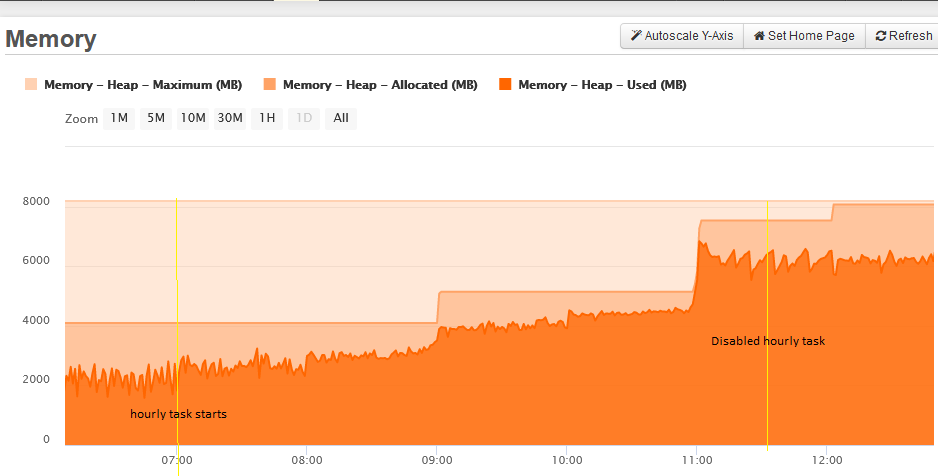
As I say, the task is complex and we’re not sure which specific element is responsible, but it runs in a separate thread for one thing and performs various operations using parallel closures, so it seems likely it’s related to threading.
By accident I also discovered something strange. The task needed to be run again so we decided to do it manually so we could observe the expected rise in memory usage. Although not sure I’d have the expertise to understand it, I thought I’d try the Heap Dump extension Zac mentioned a while ago. I installed it but couldn’t see any way of accessing it or find any docs, so uninstalled it.
But when I returned to my FR graphs I saw that memory usage had dropped significantly at the exact moment of installing the extension. Note I didn’t run the heap dump tool, just installed it. I’ve replicated it since: just installing the extension clears out a bunch of memory. Perhaps installing any extension has this effect?
Not only that, but with the memory cleared we ran the hourly task again manually and this time GC seemed to be more effective afterwards as illustrated by this graph:
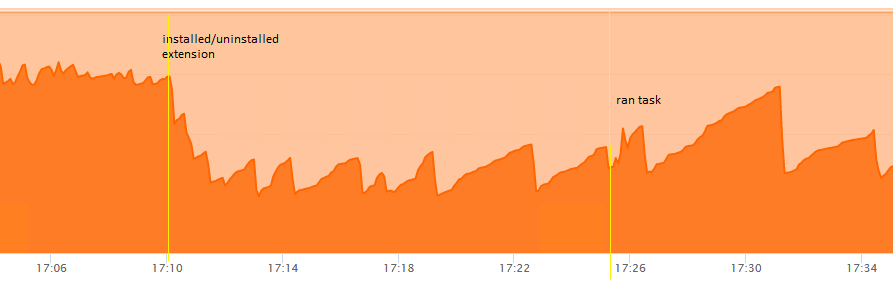
I’m not sure yet what to conclude. There’s clearly something wrong with Lucee versions 5.3.5+ in certain conditions, and our experience suggests it may be related to threads/parallelism.
But at least we know enough now to be able to control it, which makes testing easier.
@ggriffit does any of this make sense in your context?