[Stack: OS: Windows; Java:OpenJDK 8u252-b09; Tomcat: 9.0.31]
Has anyone else had memory problems with the latest stable release 5.3.6.61?
We upgraded one of our prod machines to it from 5.3.4.85 ten days ago and it’s been fine.
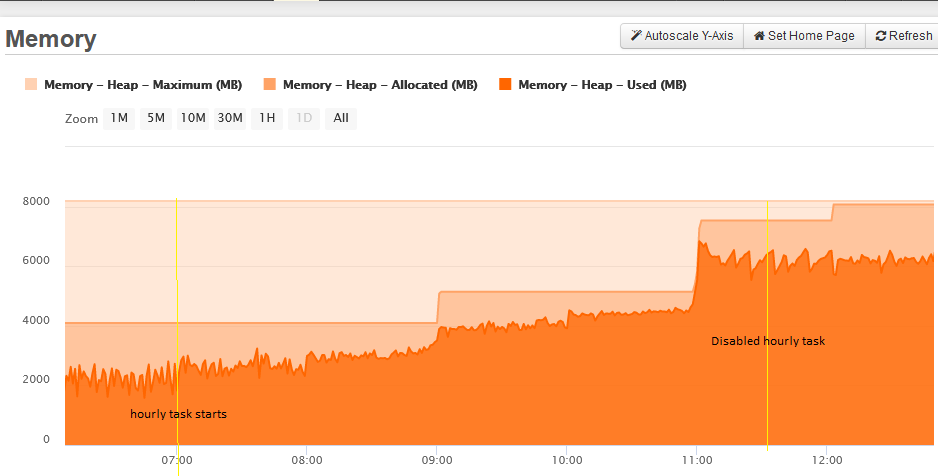
But on our other one it seemed to result in a memory leak of some kind. This machine is quite busy but only during local business hours. We installed it on Sunday and all seemed well when quiet. But at 8am on Monday memory use started climbing abnormally.
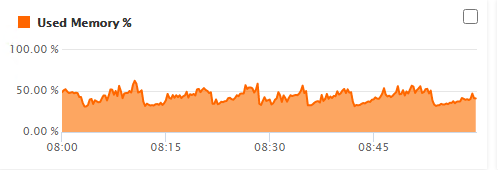
Here’s what it normally looks like at that time on a weekday (running 5.3.4.85). There is 8GB allocated which is more than adequate. You can see Garbage Collection running normally, and this is the general pattern for the rest of a typical day.
But this is what we saw with 5.3.6.61. GC doesn’t seem to be recovering very much space:
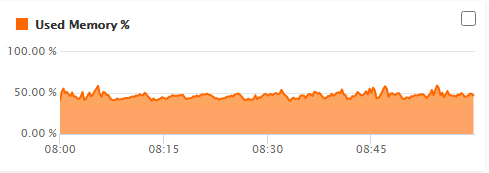
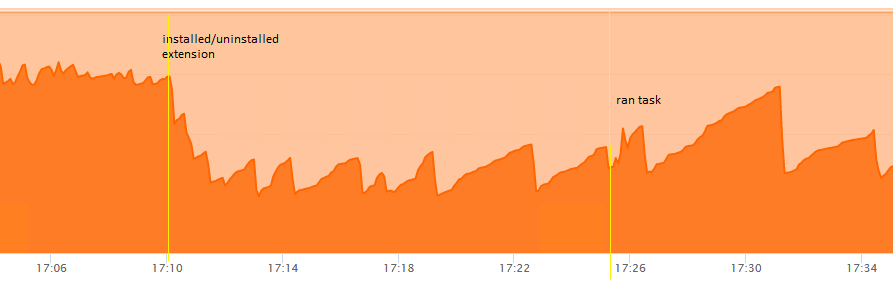
I ran GC manually (using FR) but it didn’t have much effect either.
By mid afternoon it had climbed further:
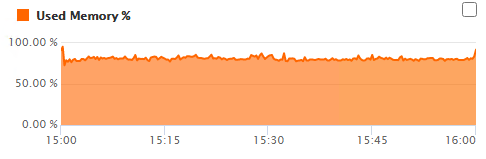
…until by the end of the day the heap was full, the server ground to a halt and had to be restarted:
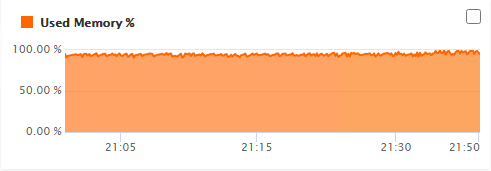
The same pattern played out again today more quickly so we’ve gone back to 5.3.4.85 which has been solid for over 2 months (despite being a “snapshot”).
Perhaps it’s related to this issue, although this is definitely heap memory, not metaspace. Or maybe this one?