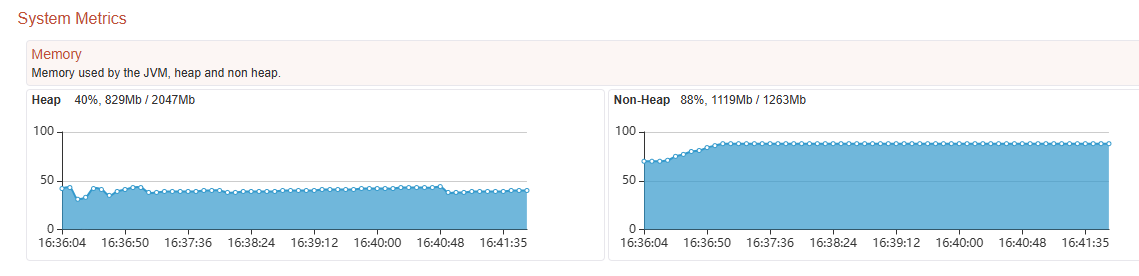
Hi, we’re experiencing some memory issues on our DEV-server. It was a fresh install from a Lucee 6 stable release, with the 5.4.x JAR as a base loader. I then upgraded to 6.2.0.321 and replaced the 5.4.x. JAR to the 6.0.1.83 JAR, as we have that on our LIVE server as well. Since then the memory continually grows during the week, with some development going on. On a Friday it usually is ok, but come Monday morning Tomcat no longer is present at the designated port, giving an error in the browser saying nothing is listening. The memory of the Windows service has then grown to 4,5GB, whilest it ususally runs on 1GB. The Windows service is still running, but unresponsive to the browser. Nothing is done in the weekend, no work on the server and there are only some scheduled tasks that run on a timely basis. What could be the culprit? For now I’ve downgraded to 6.1.0.243, as I read somewhere that others had issues with the version in between, 6.1.1.118 (also in relation to scheduled tasks?).
Stack:
Windows 2022