OS : Windows 10 Enterprise 64bit
Java Version : 11.0.25 (Eclipse Adoptium) 64bit
Lucee Version : 6.1.1.118
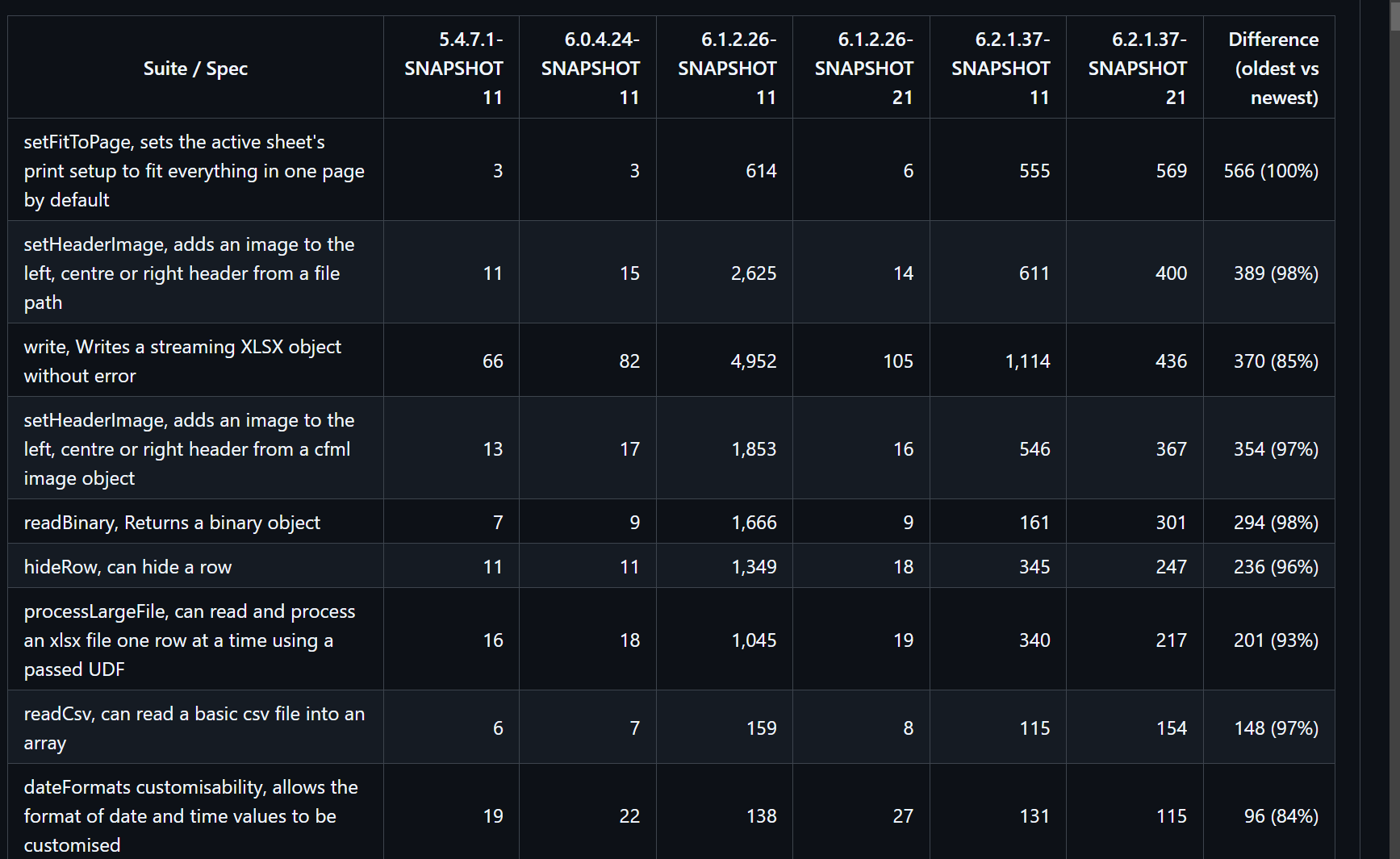
We use the Apache POI library to build excel files and noticed quite a bit of performance drop when using lucee 6.1.x. We’re using the streaming SXSSF workbook, as is recommended for large files.
The following example is running locally using Commandbox. I created a fake dataset with about 48k rows with 17 columns (this mirrors the data set size we’re seeing in our production servers that gave us notice to the issue).
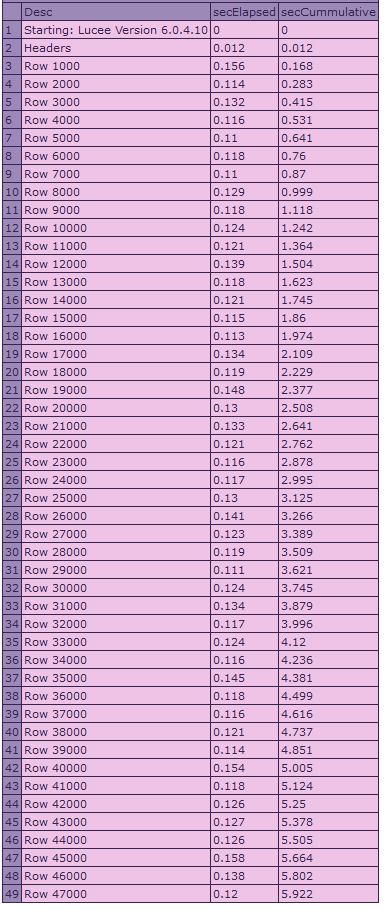
In Lucee 6.0.4.10, it is averaging around 0.12 seconds per 1000 rows on my machine. The whole 48k dataset takes about 6-7 seconds total.
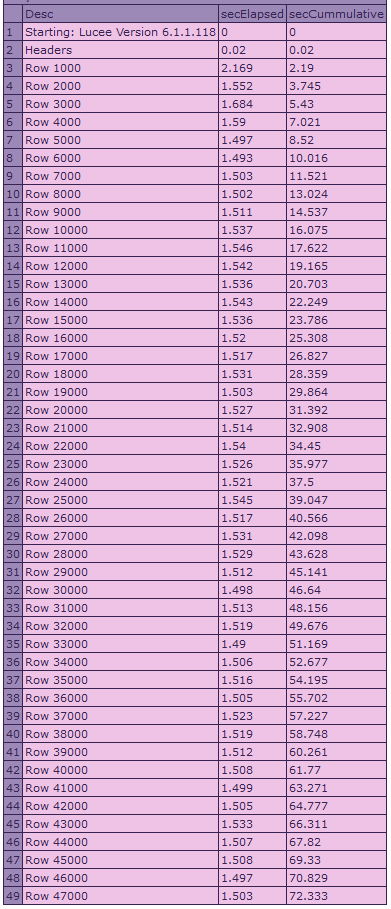
Updating to Lucee 6.1.1.118, the same code averages 1.5 seconds per 1000 rows, with a total time around 70-75 seconds.
I know a lot of work has been done to how Lucee is interacting with Java objects in Lucee 6. But the performance hit for this case is pretty severe. I’m wondering if there is something we should be doing differently?
I’ve included sample code to reproduce the issue. It requires the cfspreadsheet extension to be installed.
qTimes = queryNew('Desc,secElapsed,secCummulative', 'varchar,decimal,decimal');
qTimes.addRow({ desc = 'Starting: Lucee Version #SERVER.lucee.version#', secElapsed = 0, secCummulative = 0 });
row = 1;
qData = queryNew(
'col_1,col_2,col_3,col_4,col_5,col_6,col_7,col_8,col_9,col_10,col_11,col_12,col_13,col_14,col_15,col_16,col_17'
,'integer,varchar,integer,date,integer,decimal,varchar,varchar,varchar,varchar,integer,date,integer,decimal,varchar,varchar,varchar'
);
for(i = 1; i <= 47008; i++ ) {
// Just filling query with random test data
qData.addRow({
col_1 = row++
,col_2 = 'foo'
,col_3 = randRange(1, 100)
,col_4 = dateAdd('d', i-1, createDate(2024,1,1))
,col_5 = i % 3
,col_6 = i * (pi()-2)
,col_7 = 'foo'
,col_8 = 'bar'
,col_9 = 'baz'
,col_10 = 'foo'
,col_11 = randRange(1, 10000)
,col_12 = dateAdd('d', -1*(i-1), createDate(2024,1,1))
,col_13 = i % 3
,col_14 = i * (pi()-2)
,col_15 = 'foo'
,col_16 = 'bar'
,col_17 = 'baz'
});
}
tick = GetTickCount();
writeLog( 'Creating worksheet' );
wb = createObject('java', 'org.apache.poi.xssf.streaming.SXSSFWorkbook', 'cfspreadsheet' );
sheet = wb.createSheet('Example');
// Create reusable styles headerStyle, numberStyle, integerStyle, dateStyle
headerStyle = wb.createCellStyle();
headerStyle.setFillPattern(headerStyle.SOLID_FOREGROUND);
headerStyle.setFillForegroundColor(createObject("java","org.apache.poi.hssf.util.HSSFColor$GREY_25_PERCENT").getIndex());
headerFont = wb.createFont();
headerFont.setBoldweight(headerFont.BOLDWEIGHT_BOLD);
headerStyle.setFont(headerFont);
numberStyle = wb.createCellStyle();
numberStyle.setAlignment( numberStyle.ALIGN_RIGHT )
numberStyle.setDataFormat( wb.createDataFormat().getFormat( "##,####0.00" ) );
integerStyle = wb.createCellStyle();
integerStyle.setAlignment( integerStyle.ALIGN_RIGHT )
integerStyle.setDataFormat( wb.createDataFormat().getFormat( "##,####0" ) );
dateStyle = wb.createCellStyle();
dateStyle.setAlignment( numberStyle.ALIGN_RIGHT )
dateStyle.setDataFormat( wb.createDataFormat().getFormat( "m/d/yyyy" ) );
writeLog( 'output headers - #(getTickCount()-tick)/1000#s' );
// Create Header Rows
currentRowNum = 0;
row = sheet.createRow(currentRowNum++);
col = 0;
for( label in qData.columnArray() ) {
cell = row.createCell(col++); cell.setCellStyle(headerStyle); cell.setCellValue("Column #ucase(label)#");
}
secElapsed = (getTickCount()-tick)/1000;
qTimes.addRow({ desc = 'Headers', secElapsed = secElapsed, secCummulative = secElapsed });
// Loop over query data
writeLog( 'Start output data - #(getTickCount()-tick)/1000#s' );
prevTick = getTickCount();
cfloop( query = qData ) {
if (qData.currentRow % 1000 == 0 ) {
secElapsed = (getTickCount()-prevTick)/1000;
secCummulative = (getTickCount()-tick)/1000;
writeLog( 'output data #qData.currentRow# - #secCummulative#s - #secElapsed#s' );
qTimes.addRow({ desc = 'Row #qData.currentRow#', secElapsed = secElapsed, secCummulative = secCummulative});
prevTick = getTickCount();
}
col = 0;
row = sheet.createRow(currentRowNum++);
cell = row.createCell(col++); cell.setCellValue(qData['col_1']); cell.setCellStyle(integerStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_2']);
cell = row.createCell(col++); cell.setCellValue(qData['col_3']); cell.setCellStyle(integerStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_4']); cell.setCellStyle(dateStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_5']); cell.setCellStyle(integerStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_6']); cell.setCellStyle(numberStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_7']);
cell = row.createCell(col++); cell.setCellValue(qData['col_8']);
cell = row.createCell(col++); cell.setCellValue(qData['col_9']);
cell = row.createCell(col++); cell.setCellValue(qData['col_10']);
cell = row.createCell(col++); cell.setCellValue(qData['col_11']); cell.setCellStyle(integerStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_12']); cell.setCellStyle(dateStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_13']); cell.setCellStyle(integerStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_14']); cell.setCellStyle(numberStyle);
cell = row.createCell(col++); cell.setCellValue(qData['col_15']);
cell = row.createCell(col++); cell.setCellValue(qData['col_16']);
cell = row.createCell(col++); cell.setCellValue(qData['col_17']);
}
// Output to file
baos = createObject("java", "java.io.ByteArrayOutputStream").init();
wb.write(baos);
baos.flush();
fileWrite('C:\temp\report.xlsx', baos.toByteArray());
// Display times
writeDump( var="#qTimes#", output="browser", abort="true");
results from 6.1:
Results from 6.0:
Appreciate any guidance on this.