Forgive the naive question:
Isn’t obj.hashCode() used for this scenario of determining dupe objects?
No, not always. For most of the built in JDK types, this is true. But Lucee itself does not implement a hashcode method for queries for example:
var qry1 = queryNew('col1','string',[[1],[2]])
var qry2 = queryNew('col1','string',[[1],[2]])
dump( qry1 )
dump( qry2 )
dump( qry1.hashCode() ) // Not the same as qry2
dump( qry2.hashCode() ) // Not the same as qry1
1 Like
Wouldn’t the contents (objects) in the query columns have the same hashCode() value though?
Interesting that you have to be very explicit with the row … ![]()
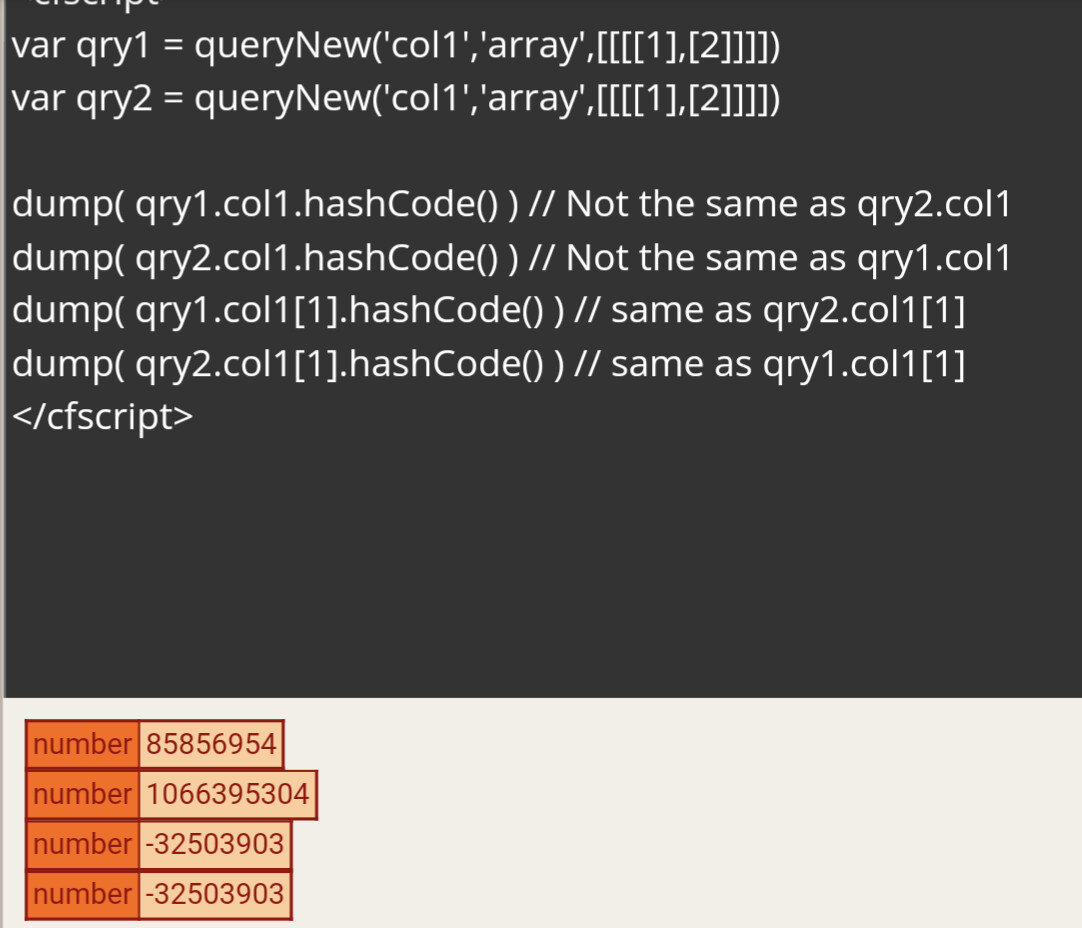
You didn’t seem to understand what I said. Simple types from the JDK yes, but all possible Java classes available in Lucee which can be crammed into a query cell, no. This actual post is all about cramming an entire query object into the cell of another query object. So in that case, the value of a cell in the outer query does NOT have the same hash code of another query object containing the same data elsewhere. Would it be possible for Lucee to implement this? Yeah, probably. But it hasn’t. And queries are just one thing. There are many other things you can stick into a query cell. CFML Structs are another example where hash codes don’t match for two structs containing the same data.
Gotcha. So some objects will work others, “It’s complicated”.
1 Like
I moved this to a new thread to not clutter the previous one. It may be possible to go through all of Lucee’s common datatypes and implement better hashcode methods. A CFML array, for example, has a “working” hashcode method, but that’s because ArrayImpl ultimately inherits its hashcode method from java.util.AbstractList. StructImpl however appears to just inherit its from java.lang.Object. That means two CFML arrays of strings will have the same hashcode, but two CFML arrays with at least one CFML struct will not!
StructImpl has a commented out hashcode method, so I assume Micha worked on this at one point, but it caused issues and he gave up. I have seen endless recursion happen before inside of hashcode() methods on objects that have circular references which may have led him to just comment them out.
It would certainly help simplify query of query partitioning if I could trust the hashcodes-- and heck-- maybe for simple queries that don’t have complex values, I can. I should do some testing on that as it would perform better than the MD5 hash I currently do on the string representation of the data!
1 Like
In code based on my understanding:
a1 = ['foo','baz','bar']
a2 = ['foo','baz','bar']
dump label='Two arrays of strings'
var='#a1.hashCode() EQ a2.hashCode()#'; // true
s1 = {a:'struct'}
s2 = {a:'struct'}
s3 = {'A':'struct'}
s4 = {'a':'struct'}
dump label='Two structs'
var="#[
s1.hashCode() EQ s2.hashCode(), // false
s1.hashCode() EQ s3.hashCode(), // false
s1.hashCode() EQ s4.hashCode(), // false
s2.hashCode() EQ s3.hashCode(), // false
s2.hashCode() EQ s4.hashCode(), // false
s3.hashCode() EQ s4.hashCode() // false
]#";
a3 = ['foo','baz','bar',s1]
a4 = ['foo','baz','bar',s2]
dump label='Two arrays with one struct'
var='#a3.hashCode() EQ a4.hashCode()#'; // false
Alright, so it’s complicated … how can we simplify?
If I was asked to “store this data, then update it only if it changes” I would make it into a string or calculate a hash somehow ![]() so it could be stored.
so it could be stored.
That got me to thinking about the following:
// (continuing code from above)
dump label='Two arrays with one struct serialized'
var='#serialize(a3).hashCode() EQ serialize(a4).hashCode()#'; // true
dump label='Two arrays with one struct toString'
var='#a3.toString().hashCode() EQ a4.toString().hashCode()#'; // true
dump label='Two serialized structs (case sensitive so s4 will not match)'
var="#[
serialize(s1).hashCode() EQ serialize(s2).hashCode(), // true
serialize(s1).hashCode() EQ serialize(s3).hashCode(), // true
serialize(s1).hashCode() EQ serialize(s4).hashCode(), // false
serialize(s2).hashCode() EQ serialize(s3).hashCode(), // true
serialize(s2).hashCode() EQ serialize(s4).hashCode(), // false
serialize(s3).hashCode() EQ serialize(s4).hashCode() // false
]#";
dump label='Two serialized structs (case insensitive so all match)'
var="#[
lcase(serialize(s1)).hashCode() EQ lcase(serialize(s2)).hashCode(), // true
lcase(serialize(s1)).hashCode() EQ lcase(serialize(s3)).hashCode(), // true
lcase(serialize(s1)).hashCode() EQ lcase(serialize(s4)).hashCode(), // true
lcase(serialize(s2)).hashCode() EQ lcase(serialize(s3)).hashCode(), // true
lcase(serialize(s2)).hashCode() EQ lcase(serialize(s4)).hashCode(), // true
lcase(serialize(s3)).hashCode() EQ lcase(serialize(s4)).hashCode() // true
]#";
Now, does this work for all data types? I’m not sure.
My hope though is that it’s not as complicated as first thought.
I see a defect ticket in my future as I’m certain we have code that uses .equals() and the datatype is a struct. It worked in ACF … ![]()
Well that’s a relief that equals works. ![]()
s1.equals(s2), // true
s1.equals(s3), // true
s1.equals(s4), // true
s2.equals(s3), // true
s2.equals(s4), // true
s3.equals(s4) // true
Yup, this is a hard problem to solve. If you look at the TestBox expectation library, we did a bunch of work to be able to compare different data structures manually.
Yes, that’s because Lucee’s StructImpl class has its own equals() method. It doesn’t use hashcode though, it uses a hand baked method
@Override
public boolean equals(Object obj) {
if (!(obj instanceof Collection)) return false;
return CollectionUtil.equals(this, (Collection) obj);
}