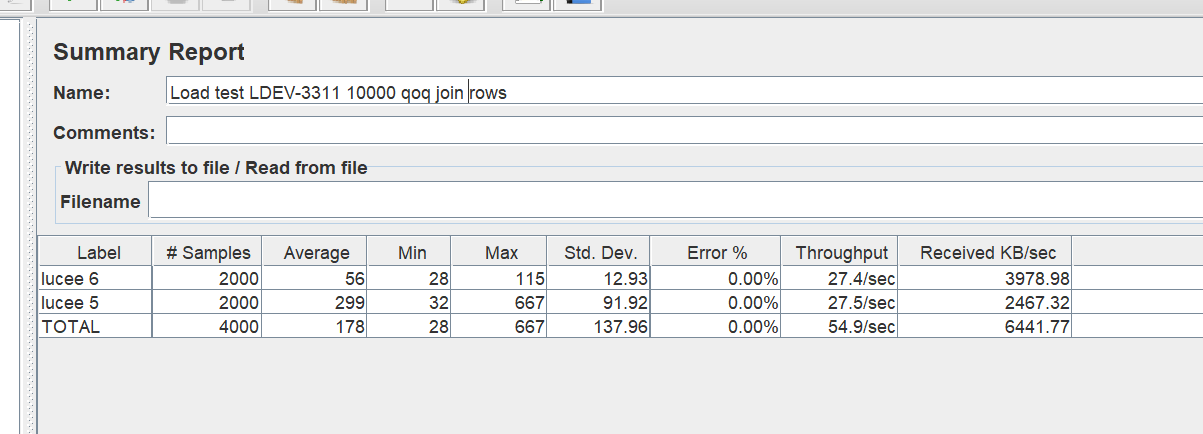
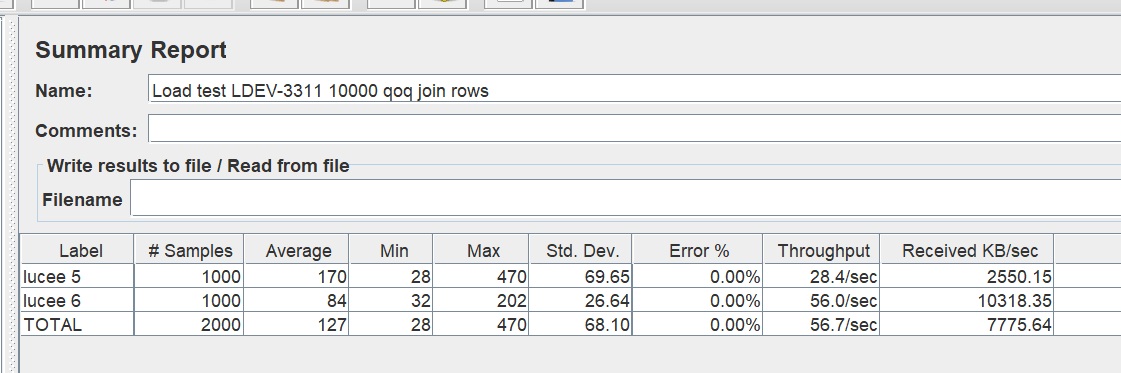
I’ve been working on optimizing the loading of temp tables into HSQLDB for a few years
finally got it all working (more or less)
some stats and a sample .lco on the ticket, I’d been keen to have some other people test it out?
https://luceeserver.atlassian.net/browse/LDEV-3317
this only affects multi table QoQ
the main changes are as follows
- only the required columns are loaded into the temp database (a view is created and asked which columns are needed to perform the query)
- the synchronized lock is now only around loading data, not the actual executing of the query of query, basically all multi table QoQ is single threaded on an instance
- if you are querying from large tables with lots of columns, it should be far more efficient
- a bonus here is sometimes the old engine had problems ignoring columns it couldn’t handle, which weren’t even required for the QoQ! i.e. incompatible data type in operation (problem was the id columns differ in type, even tho they aren’t even referenced, this is solved by this PR too)
- refactoring
this is with a simple example with optimized column loading disabled
[java] [script] Found 1 tests to run, filter took 591ms
[java] [script] test.tickets.LDEV3311 q1 has 5 rows
[java] [script] q2 has 1048581 rows
[java] [script] SQL: CREATE TABLE "Q1" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] QoQ HSQLDB CREATED TABLES: SELECT q1.id FROM q1 where id in (select id from q1 )
[java] [script] getUsedColumnsForQuery: took 6
[java] [script] Populate Table: [q1] with [5] rows, [3] columns, took 3ms
[java] [script] SQL: CREATE TABLE "Q2" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] QoQ HSQLDB CREATED TABLES: SELECT q2.id FROM q2 where id in (select id from q2 )
[java] [script] getUsedColumnsForQuery: took 1
[java] [script] Populate Table: [q2] with [1048581] rows, [3] columns, took 803ms
[java] [script] SQL: CREATE TABLE "Q1" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] SQL: CREATE TABLE "Q2" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] QoQ HSQLDB CREATED TABLES: SELECT q1.id, q2.id as id2 FROM q2, q1 where q1.id = q2.id group by q1.id, q2.id
[java] [script] getUsedColumnsForQuery: took 4
[java] [script] Populate Table: [q1] with [5] rows, [3] columns, took 1ms
[java] [script] Populate Table: [q2] with [1048581] rows, [3] columns, took 766ms
[java] [script] (1 tests passed in 4,213 ms)
this is with a simple example with optimised column loading enabled
[java] [script] Found 1 tests to run, filter took 655ms
[java] [script] test.tickets.LDEV3311 q1 has 5 rows
[java] [script] q2 has 1048581 rows
[java] [script] SQL: CREATE TABLE "Q1" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] QoQ HSQLDB CREATED TABLES: SELECT q1.id FROM q1 where id in (select id from q1 )
[java] [script] getUsedColumnsForQuery: took 6
[java] [script] Populate Table: [q1] with [5] rows, [1] columns, took 2ms
[java] [script] SQL: CREATE TABLE "Q2" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] QoQ HSQLDB CREATED TABLES: SELECT q2.id FROM q2 where id in (select id from q2 )
[java] [script] getUsedColumnsForQuery: took 1
[java] [script] Populate Table: [q2] with [1048581] rows, [1] columns, took 550ms
[java] [script] SQL: CREATE TABLE "Q1" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] SQL: CREATE TABLE "Q2" ("ID" INTEGER,"NAME" VARCHAR_IGNORECASE,"DATA" VARCHAR_IGNORECASE)
[java] [script] QoQ HSQLDB CREATED TABLES: SELECT q1.id, q2.id as id2 FROM q2, q1 where q1.id = q2.id group by q1.id, q2.id
[java] [script] getUsedColumnsForQuery: took 3
[java] [script] Populate Table: [q1] with [5] rows, [1] columns, took 0ms
[java] [script] Populate Table: [q2] with [1048581] rows, [1] columns, took 663ms
[java] [script] (1 tests passed in 3,948 ms)
As we have upgraded HSQLDB to 2.7.2, something don’t work like they used to, it’s a bit more strict
So odd things like duplicate column names don’t work, just add a column alias