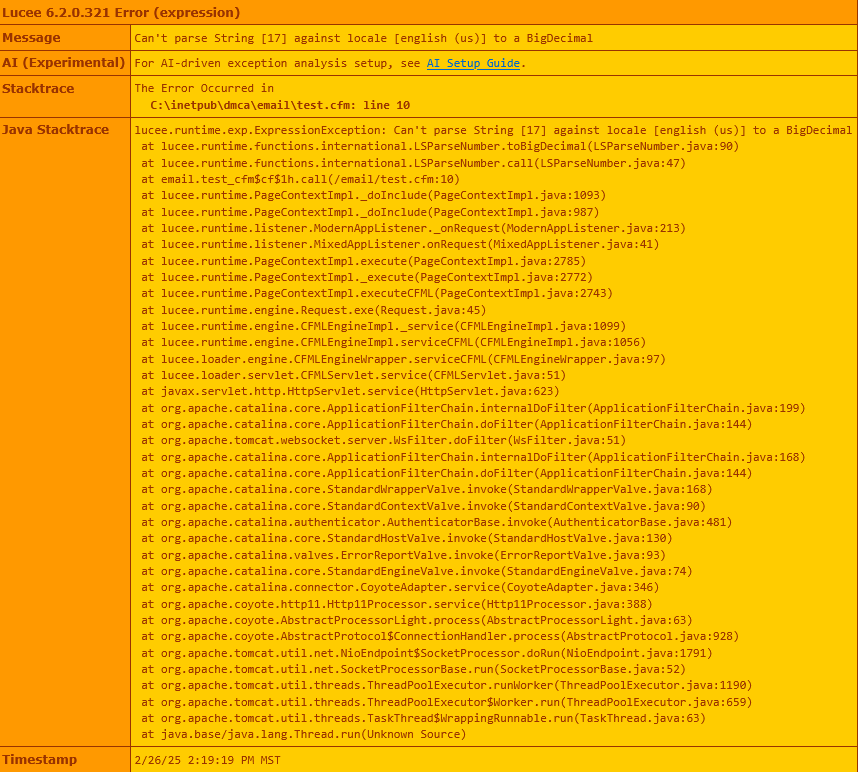
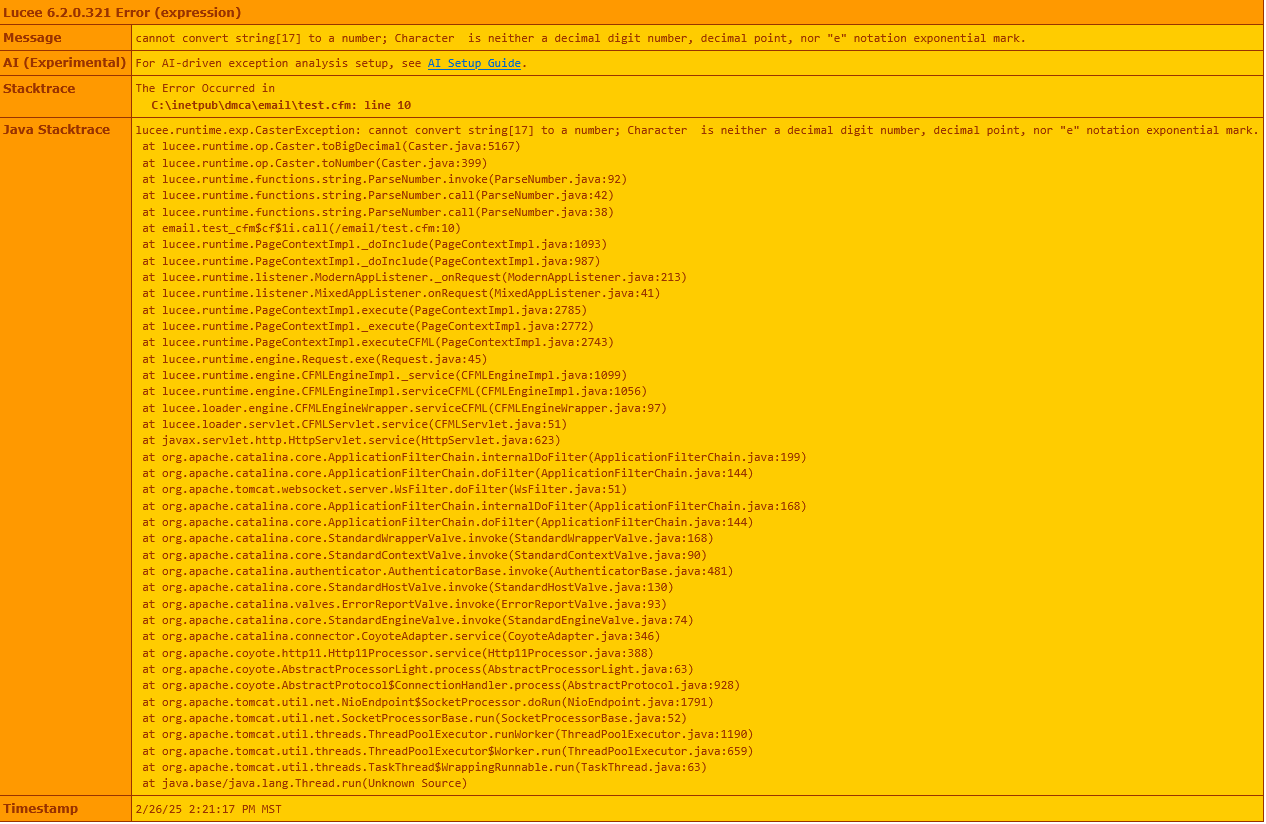
Lucee version 6.2.0.321, although only upgraded last night (from version 6.1.x I believe) while trying to resolve the issue that follows.
Apache Tomcat/9.0.89
11.0.22 (Eclipse Adoptium) 64bit
Windows Server 2016 (10.0) 64bit
I am developing an application that calls and consumes the Microsoft Graph API. I have been able to obtain an access token and have made numerous successful calls to the API.
My problem comes in when I try to make a call to the API using cfhttp and the $count URL segment (more on that here). The returned cfhttp structure returns a filecontent member that appears to be just the number, as is expected from this call…
Notice what appears to be an extra space in the parseNumber exception message, between “Character” and “is”.
I have tried a number of things and have spent many hours trying to find the cause and solution to this problem. I am hoping (against hope, it feels like) that someone here may have the wisdom that I do not. I am up against a deadline, and am concurrently trying to develop a workaround. If anyone can provide some quick feedback, that would be wonderful!
Ok, you mean the server heder content-type is set to html/text then and not application/json, right? Then that is an api issue. I’m not at my notebook right now, but I’d try it anyway and also as a second option trimming it before consuming anything.
Or are just saying it is of text/html becaue it is not sent as a key/value pair?
really strange, Lucee does a trim internally before using the parser.
we use a different parser because we switched from double to BigDecimal numbers by default.
But the parser used is from the JVM itself, also the message comes from the JVM. @mbuckman can you please copy/paste the exception message here or better write it to a file with charset UTF-8 and attach the file here
okay i can reproduce the issue with this (in Java)
public static void main(String[] args) throws CasterException {
// Test cases with various invisible characters
print.e(toBigDecimal("17")); // Normal case, should work
print.e(toBigDecimal("17\u200B")); // Zero-width space
print.e(toBigDecimal("1\u00A07")); // Non-breaking space
print.e(toBigDecimal("1\u20087")); // Punctuation space
print.e(toBigDecimal("17\uFEFF")); // Zero-width no-break space (BOM)
print.e(toBigDecimal("17\u200C")); // Zero-width non-joiner
print.e(toBigDecimal("17 ")); // Regular space at the end (should be trimmed)
print.e(toBigDecimal(" 17")); // Regular space at the beginning (should be trimmed)
// Also test with your actual problematic string if possible
// For example, this might be coming from a file or user input
}
Sorry everyone. I just saw the activity on this post. I will try to spin up a VM and give it a shot this weekend, maybe with both 6.1 and 6.2.1.45-SNAPSHOT. Thanks for the diagnostic work, @micstriit!