In the middle of the night I woke to a RED ALERT from UptimeDoctor.com. In the Pushover app on my phone I literally configured a Star Trek red alert mp3 for fun, though it’s only humorous after the issue is resolved! ![]() It’s quite surreal, especially when in a half-dream state, when that old familiar sound represents an actual emergency and I feel like I’m on the bridge of the Enterprise about to get vaporized for reals.
It’s quite surreal, especially when in a half-dream state, when that old familiar sound represents an actual emergency and I feel like I’m on the bridge of the Enterprise about to get vaporized for reals. ![]()
Lucee was unresponsive and my only clue initially was Java Heap Out of Memory.
All was well after restarting Lucee, then about an hour of analyzing resource logs also revealed high CPU from Lucee/Java, the baseline of which is always a mere 1%.
After a few more hours of sleep, then reviewing Apache logs, I figured out it was AI BOTS GONE WILD. I also found I’m by far not the only one affected. Turns out the bots are having a huge global impact due to their use of Amazon AWS.
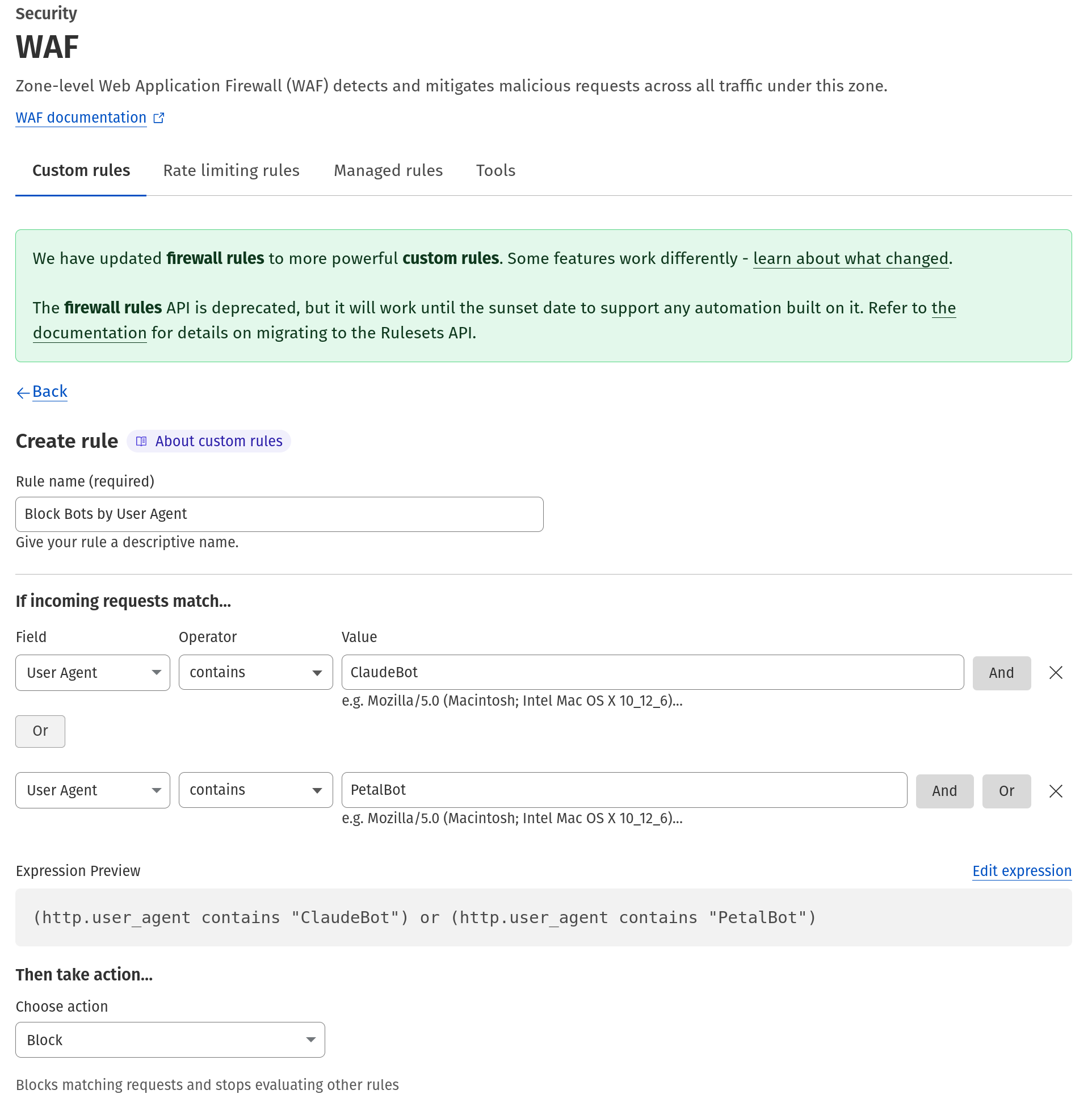
Then I worked on how best to stop them. Fortunately they’re at least nice enough to identify themselves, but the usual means of robots.txt or Apache config don’t work due to mod_proxy sending the requests to Lucee before those are processed.
One option could have been for my Lucee apps to deal with it. Not only would that require extra coding, but more importantly even when the bots are blocked, they’re still using Java resources.
mod_security to the rescue! Since I use OWASP CRS, after hours of digging and plenty of frustration, I finally found a simple text file where I appended the list of bots I needed to block:
/etc/apache2/conf.d/modsec_vendor_configs/OWASP3/rules/crawlers-user-agents.data
(location is likely different on non-cPanel servers)
I spent a total of nearly NINE HOURS on this quite aggravating incident and my purpose for posting is to hopefully help others feeling the same pressure to keep their servers and apps running smoothly in the face of the AI invasion!
![]()
![]()
![]()