This seems like a regression issue.
Lucee 5.3.6.61
Apache Tomcat/9.0.31
11.0.6 (AdoptOpenJDK) 64bit
CentOS Linux 7.8.2003
Recently updated from Lucee 5.2.8.50 to 5.3.6.61 because a production web server started to crash for unknown reasons. Upgrade went smooth. However, about a month later started to have performance problems related to cf_client_data.
Clustered setup with 2 web servers / 2 db servers (one for data - one for session)
The performance problem was isolated to the session database. In AWS CloudWatch, I could see the Average Queue Length growing - and spiking every 61 minutes. I traced those queries and it was:
Time: 200805 16:59:00
Query_time: 239.316670 Lock_time: 0.000045 Rows_sent: 7465744 Rows_examined: 7565860
SET timestamp=1596661140;
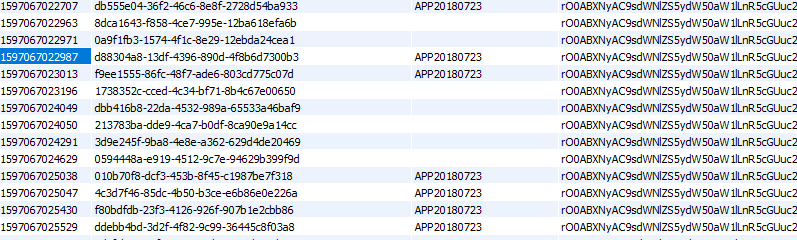
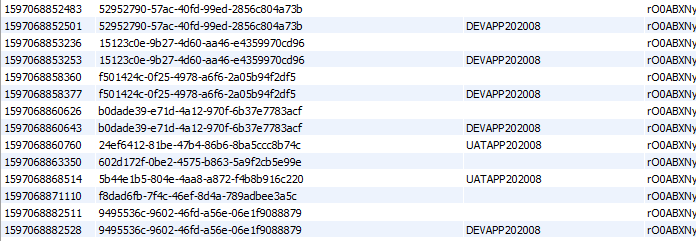
SELECT cfid, name FROM cf_client_data WHERE expires <= ‘1596660900852’;
Looks like I was missing a vital index - which has been added using:
CREATE UNIQUE INDEX ix_cf_client_data ON cf_client_data(cfid, name, expires)
QUESTION: Why wasn’t this a problem in 5.2.8.50???
The index was missing then too. Everything else is 100% same. No changes in user volumes.
We failed back to 5.2.8.50 last night. I trucated the cf_client_data tables for both versions. This morning the 5.2.8.50 is an expected size. The 5.3.6.61 cf_client_data table is growing again.
Is this a possible bug in 5.3.6.61? cf_client_data is not deleting? I see delete statements running every 61 minutes - such as this:
DELETE FROM cf_client_data WHERE cfid=‘cab5cb06-1f5f-47cd-95e3-c49a4072c43b’ and name=‘APP20180723’
— but why would the record count have grown so dramatically over a month. It was up to over 7,000,000 records in cf_client_data when it finally crashed last night… Again, none of this was happening in 5.2.8.50 with the EXACT same hardware / application set up. Again, this seems like a regression issue.