https://poi.apache.org/apidocs/5.0/org/apache/poi/xwpf/usermodel/XWPFRun.html
createdoc.cfm (286 Bytes)
PoiComponent.cfc (1.9 KB)
Managed to resolve the line breaks, next stop, formatting.
1 Like
Unfortunately I have ran aground with this. As I have to admit I am out of my depth with this, I’ve had to use Grok and ChatGPT to get this far and also try to find a solution, they just keep making changes and creating different errors.
I have managed to get it to set fonts, add the right paragraph spacing, and also work with bold.
The next thing was adding basic bullet points “-” but as soon as I add the bullet point into the createdoc.cfm as inputString = "<b>Hello World!</b>" & chr(10) & chr(10) & "This is line three";
it fails with the error below
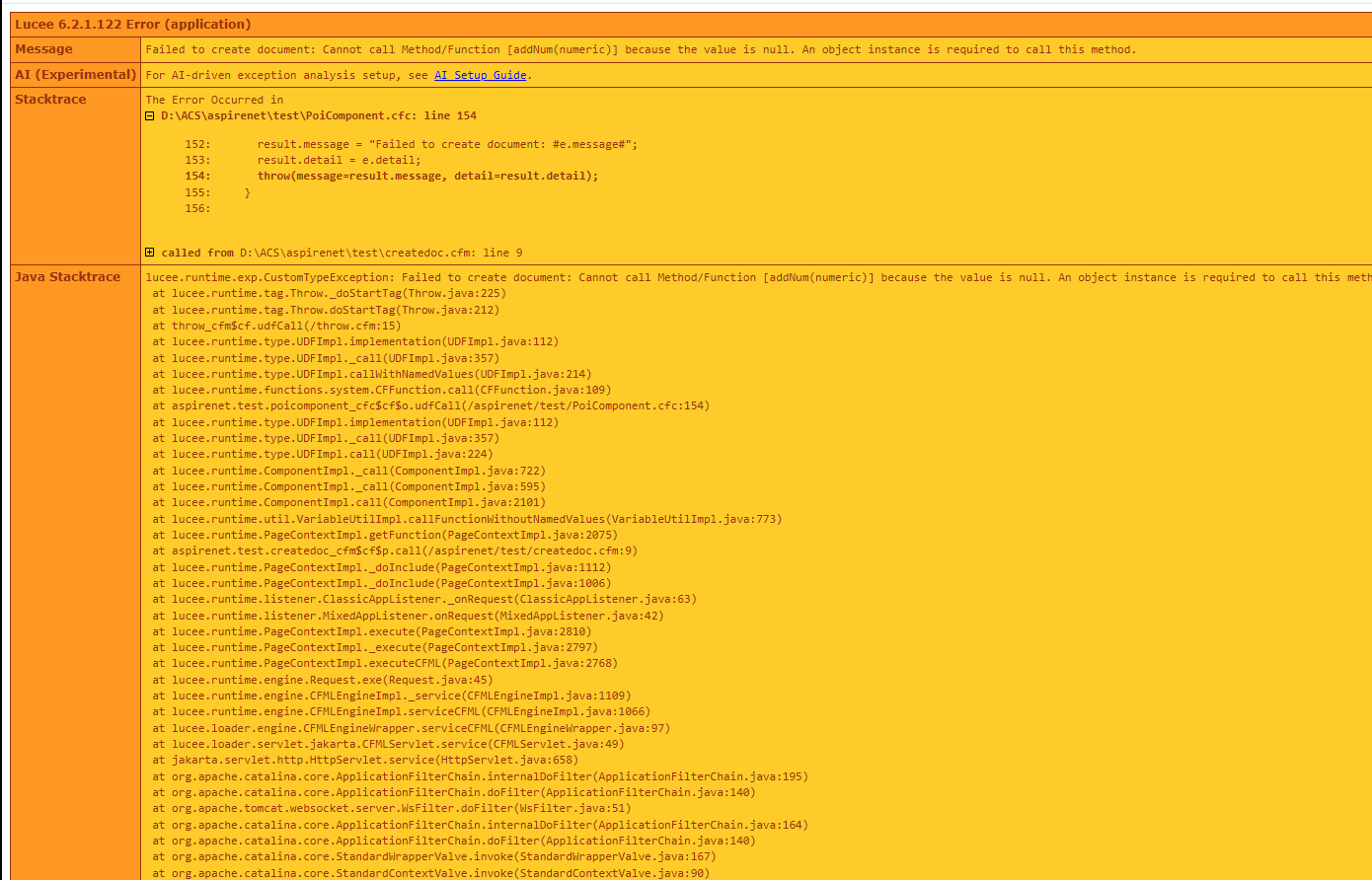
I’ve attached the files that do work until you add the bullet tag.
createdoc.cfm (293 Bytes)
PoiComponent.cfc (5.6 KB)
I have spent hours on end with the LLM’s sending me round in circles. They have mentioned issues with the classes, or Mavan, here’s a list Grok suggests could be the issue
- Missing or corrupted Maven dependencies in C:\lucee\tomcat\lucee-server\mvn
- Version mismatch between xmlbeans:5.3.0 and required ooxml-schemas:1.4 (should be 3.1.0)
- Invalid poi-ooxml-full:5.4.1 dependency causing classpath issues
- Classpath conflict from manual JARs in C:\lucee\tomcat\lib
- Lucee server cache or classpath not refreshing after updates
- Apache POI 5.4.1 method incompatibility with current code logic
At some point it also mentioned that the install of Mavan with Lucee might not contain all of the necessary classes. I did install a lot of JAR files that it suggested, putting them into the Lucee Lib, but I just kept running into error after error, it even had me go back to a 10 year old JAR, nothing would work.
Did grok start talking about South Africa white genocide in the context of cfml engines? Sorry had to ask!!
Did you try as per the screenshot using the built in AI assistance within the error template?
I’m on my phone, so I can’t open your code, jars defined thru Java settings will/should/does download all the dependencies automatically, you’d get a class not found error if that’s the case
It did tell me to go buy two Tesla’s which I thought was odd and unrelated ![]()
I’ve not set up the AI, but did post the error into the AI chat’s, this is one of many errors as it kept changing the code and having me download all sorts of JARS. It was at this point I had to stop before I went insane
1 Like
Did both those LLMs point you good further sources to understand the underlying concepts better?
In fairness they did give some rather lengthy explanations, but as I was already out of my technical depth, it was difficult to understand if they were a million miles out.
first tip, you can make your caught errors much more informative by including the actual original exception, using cause=e
result.success = true;
result.message = "Document created successfully";
} catch (any e) {
result.success = false;
result.message = "Failed to create document: #e.message#";
result.detail = e.detail;
throw(message=result.message, detail=result.detail);
}
return result;
}
}
i.e.
throw(message=result.message, detail=result.detail,cause=e);
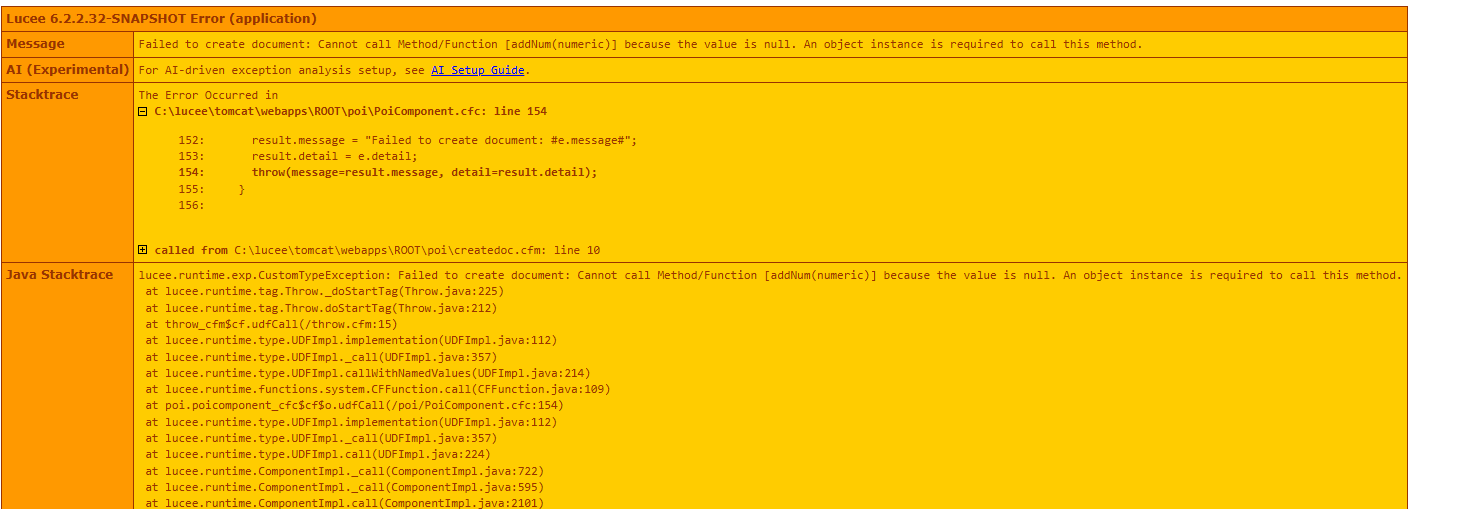
becomes
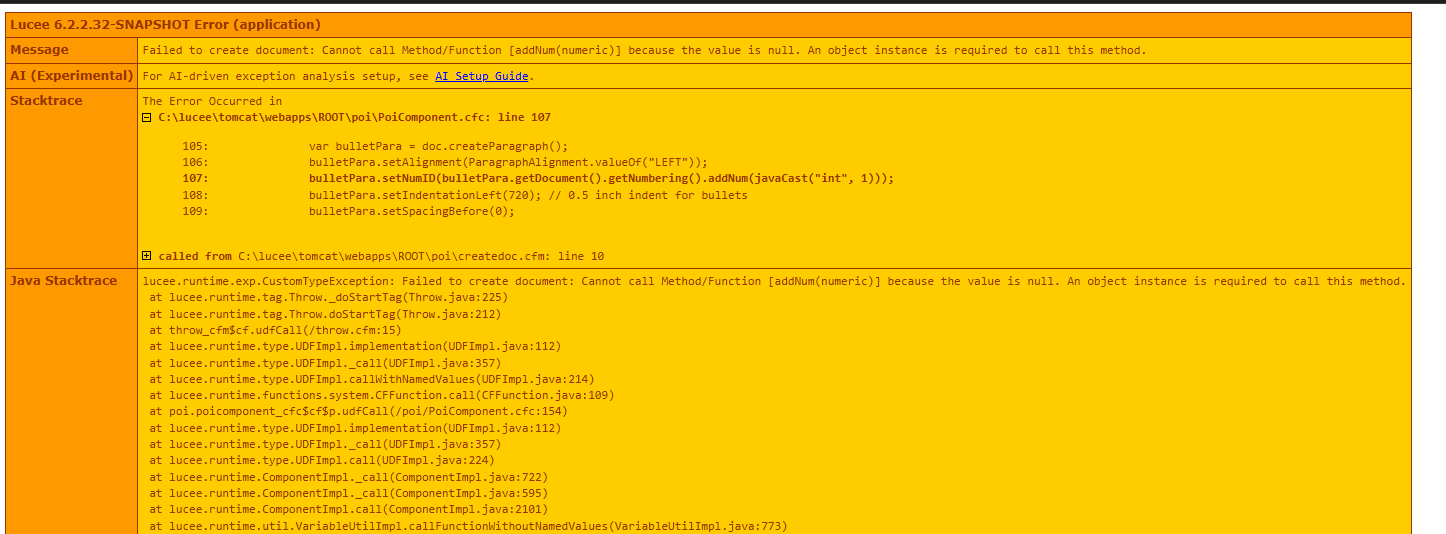
night and day huh? which also why the LLMs took you on a long journey to nowhere as they didn’t have the right context for the problem
firstly, seems bulletPara.getDocument().getNumbering() was returning a null, so I’m using an elvis ?: to default back to 0
bulletPara.setNumID( javacast("BigInteger",
(bulletPara.getDocument().getNumbering() ?: 0) + 1) ) ;
secondly, dumping out the bulletPara object tells you what method signature the java function has, Lucee does try to auto cast, but yeah, YMMV, i.e bug LDEV-5610!

so you need to cast the number to a BigInteger to match the method signature
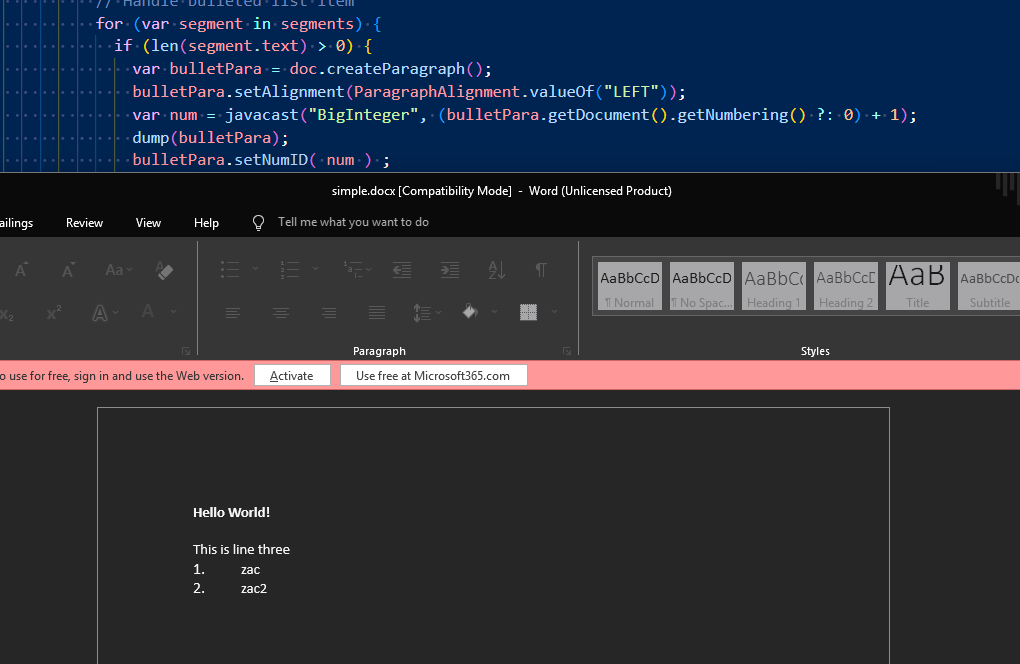
and it works
it also crashes on the first load, which is
https://luceeserver.atlassian.net/browse/LDEV-5600
https://luceeserver.atlassian.net/browse/LDEV-5601
you might find this poi based library useful too
poi-tl (poi template language) is a Word template engine that creates awesome Word documents using templates and data .
it even supports markdown to word
I create .docx with python. Very flexible and fast…
Here’s the code…
component accessors=true output=false {
/**
*
* @hint Starting python: initial setup, creating folders and setting path to python
* !!! when python is installed, make sure to pip-install: python-docx !!!
*
* @version 1.0
*
**/
public any function init() {
// actual path to Python;
variables.pythonPath = 'd:\internetsites\global\Python3124'; // mine configuration
// place where to put all files for Python (you can name it everything)
variables.pythonAppPath = expandPath("../python");
variables.jsonFilePath = variables.pythonAppPath & "\jsonfiles";
variables.pythonPatchPath = variables.pythonAppPath & "\patchfiles";
variables.pythonFilePath = variables.pythonAppPath & "\pyfiles";
variables.wordTemplatePath = variables.pythonAppPath & "\wordtemplates";
variables.wordSavedFilePath = variables.pythonAppPath & "\wordsaved";
if (! directoryExists(variables.pythonAppPath)) directoryCreate(variables.pythonAppPath);
if (! directoryExists(variables.jsonFilePath)) directoryCreate(variables.jsonFilePath);
if (! directoryExists(variables.pythonPatchPath)) directoryCreate(variables.pythonPatchPath);
if (! directoryExists(variables.pythonFilePath)) directoryCreate(variables.pythonFilePath);
if (! directoryExists(variables.wordTemplatePath)) directoryCreate(variables.wordTemplatePath);
if (! directoryExists(variables.wordSavedFilePath)) directoryCreate(variables.wordSavedFilePath);
return this;
}
/**
*
* @hint Path notation for in python-script
*
* @version 1.0
*
**/
public string function pythonPathNotation(string strInput) {
return replace(arguments.strInput, '\', '\\', 'all');
}
/**
*
* @hint Landscape or Portrait...
*
* @version 1.0
*
**/
public struct function wordDocOrientation(string strInput) {
structReturn = {
'landscape': { 'txt': 'LANDSCAPE', 'width': 297, 'height': 210, 'marginLeft': 1, 'marginRight': 1, 'marginTop': 1.8, 'marginBottom': 1.5 },
'portrait': { 'txt': 'PORTRAIT', 'width': 210, 'height': 297, 'marginLeft': 2.5, 'marginRight': 2.5, 'marginTop': 2.5, 'marginBottom': 2.5 }
}
if (!structKeyExists(structReturn, lcase(arguments.strInput))) return {};
return structReturn[lcase(arguments.strInput)];
}
/**
*
* @hint Start for generating WORD-document: settings for document
*
* @version 1.0
*
**/
public any function OverallPythonStart(struct orientationStruct={}, string strFont='Arial', numeric numFontSize=9) {
var = pythonStartString = "";
pythonStartString &= "## coding: utf-8"&Chr(13);
pythonStartString &= "import html"&Chr(13);
pythonStartString &= "from docx import Document"&Chr(13);
pythonStartString &= "from docx.enum.section import WD_ORIENT"&Chr(13);
pythonStartString &= "from docx.enum.text import WD_PARAGRAPH_ALIGNMENT"&Chr(13);
pythonStartString &= "from docx.shared import Pt, Cm, Mm, RGBColor"&Chr(13);
pythonStartString &= "from docx.oxml.ns import qn, nsdecls"&Chr(13);
pythonStartString &= "from docx.oxml import parse_xml, OxmlElement, ns"&Chr(13);
pythonStartString &= Chr(13);
pythonStartString &= "document = Document()"&Chr(13);
pythonStartString &= "style = document.styles['Normal']"&Chr(13);
pythonStartString &= Chr(13);
pythonStartString &= "font = style.font"&Chr(13);
pythonStartString &= "font.name = '#arguments.strFont#'"&Chr(13);
pythonStartString &= "font.size = Pt(#arguments.numFontSize#)"&Chr(13);
pythonStartString &= Chr(13);
// page orientation: landscape, portrait
if (structCount(arguments.orientationStruct) > 0) {
pythonStartString &= "for section in document.sections:"&Chr(13);
pythonStartString &= " section.orientation = WD_ORIENT.#arguments.orientationStruct.txt#"&Chr(13);
pythonStartString &= " section.page_width = Mm(#arguments.orientationStruct.width#)"&Chr(13);
pythonStartString &= " section.page_height = Mm(#arguments.orientationStruct.height#)"&Chr(13);
pythonStartString &= " section.top_margin = Cm(#arguments.orientationStruct.marginTop#)"&chr(13);
pythonStartString &= " section.bottom_margin = Cm(#arguments.orientationStruct.marginBottom#)"&chr(13);
pythonStartString &= " section.left_margin = Cm(#arguments.orientationStruct.marginLeft#)"&chr(13);
pythonStartString &= " section.right_margin = Cm(#arguments.orientationStruct.marginRight#)"&chr(13);
pythonStartString &= Chr(13);
}
return pythonStartString;
}
/**
*
* @hint End for generating WORD-document: run script and give back document location to download
*
* @version 1.0
*
**/
public any function overallPythonEnd(any strFile='', any batFile='', any pythonFile='', any wordFile='') {
//save .py file
fileWrite(arguments.pythonFile, arguments.strFile);
// save .bat file
var executeString = variables.pythonPath&"\python.exe "&arguments.pythonFile;
fileWrite(arguments.batFile, executeString);
// execute .bat file
cfexecute(name=arguments.batFile variable="endResult" timeout="600");
// delete both .bat and .py file
fileDelete(arguments.batFile);
fileDelete(arguments.pythonFile);
// return download-path
var returnString = fileExists(arguments.wordFile)? arguments.wordFile : '';
return returnString;
}
/**
*
* @hint Deleting empty paragraph; specially for use in cells
*
* @version 1.0
*
**/
public any function deleteParagraph() {
var = pythonStartString = "";
pythonStartString &= "def delete_paragraph(paragraph):"&Chr(13);
pythonStartString &= " p = paragraph._element"&Chr(13);
pythonStartString &= " p.getparent().remove(p)"&Chr(13);
pythonStartString &= " paragraph._p = paragraph._element = None"&Chr(13);
pythonStartString &= Chr(13);
return pythonStartString;
}
/**
*
* @hint Generate python code to display a list
*
* @version 1.0
*
**/
public any function genPythonList(array inputArray='', string docObject='document') {
var pythonString = "";
if (!arrayIsEmpty(arguments.inputArray)) {
for (var elem in arguments.inputArray) {
var strText = trim(elem);
pythonString &= arguments.docObject&".add_paragraph(html.unescape('#strText#'), style='List Bullet')"&Chr(13);
}
}
return pythonString;
}
/**
*
* @hint Generate python code to display a row list
*
* @version 1.0
*
**/
public any function genPythonRows(array inputArray='', string docObject='document') {
var pythonString = "";
if (!arrayIsEmpty(arguments.inputArray)) {
for (var elem in arguments.inputArray) {
var strText = trim(elem);
pythonString &= arguments.docObject&".add_paragraph(html.unescape('#strText#'))"&Chr(13);
}
}
return pythonString;
}
/**
*
* @hint Generate python code to display a row list; with language switch
*
* @version 1.0
*
**/
public any function genPythonRowsLanguage(array inputArray='', string docObject='document', string language='en_US') {
var pythonString = "";
if (!arrayIsEmpty(arguments.inputArray)) {
for (var elem in arguments.inputArray) {
var strText = trim(elem[arguments.language]);
pythonString &= arguments.docObject&".add_paragraph(html.unescape('#strText#'))"&Chr(13);
}
}
return pythonString;
}
/**
*
* @hint Generate python code to display text; combination with genDescriptionArray()
*
* @version 1.0
*
**/
public any function genPythonDesciption(string txtString='', string docObject='document') {
var pythonString = "";
var strLineBreak = findNoCase('row_cells', arguments.docObject)? '\n' : '';
if (arguments.txtString != '') {
var txtArray = genDescriptionArray(txtString=arguments.txtString);
var counter = 0;
for (var elem in txtArray) {
counter++;
var lineBrk = counter == 1? '' : strLineBreak;
var listEnter = elem.startOfList? ' ' : '';
var extraTxt = '';
var strText = extraTxt&trim(elem.txt);
pythonString &= arguments.docObject;
if (elem.startOfList) {
pythonString &= ".add_paragraph(html.unescape('#listEnter#'))"&Chr(13);
pythonString &= arguments.docObject;
}
if (elem.type == 'list') pythonString &= ".add_paragraph(html.unescape('#strText#'), style='#elem.listType#')";
else pythonString &= ".add_paragraph(html.unescape('#lineBrk&strText#'))";
pythonString &= Chr(13);
}
}
return pythonString;
}
public array function genDescriptionArray(string txtString='') {
var strText = arguments.txtString;
strText = replace(strText, '<p>', '', 'all');
strText = replace(strText, '<li>', '', 'all');
strText = replace(strText, '</li>', '||', 'all');
strText = replace(strText, '</p>', '||', 'all');
strText = replace(strText, '<br />', '\r', 'all')
var textArray = listToArray(strText, '||');
var actualArray = [];
var counter = 0;
var testArray = listToArray(strText, '||');
var actualArray = [];
var elemType = 'paragraph';
var listType = '';
var startOflist = false;
var counter = 0;
for (elem in textArray) {
counter++;
textArray[counter] = replace(textArray[counter], '•', '', 'all');
textArray[counter] = replace(textArray[counter], ' ', '', 'all');
if (findNoCase('<ul>', textArray[counter]) || findNoCase('<ol>', textArray[counter])) {
elemType = 'list';
listType = findNoCase('<ul>', textArray[counter])? 'List Bullet': 'List Number';
}
if (findNoCase('</ul>', textArray[counter]) || findNoCase('</ol>', textArray[counter])) {
elemType = 'paragraph';
listType = '';
}
if (findNoCase('<ul>', testArray[counter]) || findNoCase('<ol>', testArray[counter])) startOflist = true;
else startOflist = false;
var txtString = textArray[counter];
txtString = replace(txtString, '<ol>', '', 'all');
txtString = replace(txtString, '</ol>', '', 'all');
txtString = replace(txtString, '<ul>', '', 'all');
txtString = replace(txtString, '</ul>', '', 'all');
var addElem = { 'listType': listType, 'type': elemType, 'txt': txtString, 'startOfList': startOflist };
if (txtString != '') arrayAppend(actualArray, addElem);
}
return actualArray;
}
/**
*
* @hint Generate python code to display Header text
*
* @version 1.0
*
**/
public any function genPythonImage(string imagePath='', string docObject='document', numeric width, numeric height
, string measureUnit='Mm', numeric marginBottom=0) {
var image = arguments.imagePath;
var pythonString = "";
var measurement = '';
if (arguments.width != '') measurement &= ', width=#arguments.measureUnit#(#arguments.width#)';
if (arguments.height != '') measurement &= ', height=#arguments.measureUnit#(#arguments.height#)';
if (arguments.imagePath != '') {
pythonString &= arguments.docObject&".add_paragraph().add_run().add_picture(#image&measurement#)"&Chr(13);
if (arguments.marginBottom > 0) {
pythonString &= "para = #arguments.docObject#.add_paragraph('')"&Chr(13);
pythonString &= "para.paragraph_format.space_after = Cm(#arguments.marginBottom#)"&Chr(13);
}
}
return pythonString;
}
/**
*
* @hint Generate python code to display Header text
*
* @version 1.0
*
**/
public any function genPythonHeader(string txtString='', string orientation='left') {
var pythonString = "";
var orientation = arguments.orientation == 'right'? '\t\t' : arguments.orientation == 'center'? '\t' : '';
if (arguments.txtString != '') {
pythonString &= "header = document.sections[0].header"&Chr(13);
pythonString &= "header.add_paragraph('#orientation&arguments.txtString#')"&Chr(13);
pythonString &= Chr(13);
}
return pythonString;
}
/**
*
* @hint Generate python code to display Footer text; no pagination
*
* @version 1.0
*
**/
public any function genPythonFooter(string txtString='', string orientation='left') {
var pythonString = "";
var orientation = arguments.orientation == 'right'? '\t\t' : arguments.orientation == 'center'? '\t' : '';
if (arguments.txtString != '') {
pythonString &= "footer = document.sections[0].footer"&Chr(13);
pythonString &= "footer.paragraphs[0].text = html.unescape('#orientation&arguments.txtString#')"&Chr(13);
}
return pythonString;
}
/**
*
* @hint Generate python code to display Footer text; with pagination
*
* @version 1.0
*
**/
public any function genPythonFooterPaging(string txtString='', string orientation='left', string language='nl') {
var orientation = arguments.orientation == 'right'? 'RIGHT' : arguments.orientation == 'CENTER'? '\t' : 'LEFT';
var pythonStrings = {
'nl': { 'page': 'pagina', 'of': 'van' },
'en': { 'page': 'page', 'of': 'of' },
};
var startString = arguments.txtString != ''? arguments.txtString&' | ' : '';
startString &= pythonStrings[arguments.language].page&' ';
var pythonString = "";
pythonString &= "def create_element(name):"&Chr(13);
pythonString &= " return OxmlElement(name)"&Chr(13);
pythonString &= Chr(13);
pythonString &= "def create_attribute(element, name, value):"&Chr(13);
pythonString &= " element.set(ns.qn(name), value)"&Chr(13);
pythonString &= Chr(13);
pythonString &= "def add_page_number(paragraph):"&Chr(13);
pythonString &= " paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.#orientation#"&Chr(13);
pythonString &= " page_run = paragraph.add_run()"&Chr(13);
pythonString &= " t1 = create_element('w:t')"&Chr(13);
pythonString &= " create_attribute(t1, 'xml:space', 'preserve')"&Chr(13);
pythonString &= " t1.text = html.unescape('#startString#') "&Chr(13);
pythonString &= " page_run._r.append(t1)"&Chr(13);
pythonString &= " page_num_run = paragraph.add_run()"&Chr(13);
pythonString &= " fldChar1 = create_element('w:fldChar')"&Chr(13);
pythonString &= " create_attribute(fldChar1, 'w:fldCharType', 'begin')"&Chr(13);
pythonString &= " instrText = create_element('w:instrText')"&Chr(13);
pythonString &= " create_attribute(instrText, 'xml:space', 'preserve')"&Chr(13);
pythonString &= " instrText.text = 'PAGE'"&Chr(13);
pythonString &= " fldChar2 = create_element('w:fldChar')"&Chr(13);
pythonString &= " create_attribute(fldChar2, 'w:fldCharType', 'end')"&Chr(13);
pythonString &= " page_num_run._r.append(fldChar1)"&Chr(13);
pythonString &= " page_num_run._r.append(instrText)"&Chr(13);
pythonString &= " page_num_run._r.append(fldChar2)"&Chr(13);
pythonString &= " of_run = paragraph.add_run()"&Chr(13);
pythonString &= " t2 = create_element('w:t')"&Chr(13);
pythonString &= " create_attribute(t2, 'xml:space', 'preserve')"&Chr(13);
pythonString &= " t2.text = ' #pythonStrings[arguments.language].of# '"&Chr(13);
pythonString &= " of_run._r.append(t2)"&Chr(13);
pythonString &= " fldChar3 = create_element('w:fldChar')"&Chr(13);
pythonString &= " create_attribute(fldChar3, 'w:fldCharType', 'begin')"&Chr(13);
pythonString &= " instrText2 = create_element('w:instrText')"&Chr(13);
pythonString &= " create_attribute(instrText2, 'xml:space', 'preserve')"&Chr(13);
pythonString &= " instrText2.text = 'NUMPAGES'"&Chr(13);
pythonString &= " fldChar4 = create_element('w:fldChar')"&Chr(13);
pythonString &= " create_attribute(fldChar4, 'w:fldCharType', 'end')"&Chr(13);
pythonString &= " num_pages_run = paragraph.add_run()"&Chr(13);
pythonString &= " num_pages_run._r.append(fldChar3)"&Chr(13);
pythonString &= " num_pages_run._r.append(instrText2)"&Chr(13);
pythonString &= " num_pages_run._r.append(fldChar4)"&Chr(13);
pythonString &= "add_page_number(document.sections[0].footer.paragraphs[0])"&chr(13);
return pythonString;
}
/**
*
* @hint Coloring background of a cell;
*
* @comment: using multiple colors, you must define it for each cell separated by a ';' delimiter
*
* @version 1.0
*
**/
public any function cellBackgroundColor(array wichCell=[], string color='ffffff') {
var = pythonStartString = "";
var colorArray = listToArray(arguments.color, ';');
var isColorArray = arrayLen(arguments.wichCell) == arrayLen(colorArray)? true : false;
var counter = 0;
if (!arrayIsEmpty(arguments.wichCell)) {
for (var elem in arguments.wichCell) {
counter++;
var strColor = isColorArray? colorArray[counter] : colorArray[1];
pythonStartString &= "cell_xml_element = #elem#._tc"&chr(13);
pythonStartString &= "table_cell_properties = cell_xml_element.get_or_add_tcPr()"&chr(13);
pythonStartString &= "shade_obj = OxmlElement('w:shd')"&chr(13);
pythonStartString &= "shade_obj.set(qn('w:fill'), '#strColor#')"&chr(13);
pythonStartString &= "table_cell_properties.append(shade_obj)"&chr(13);
}
}
return pythonStartString;
}
/**
*
* @hint several characters-replaces;
*
* @comment: --
*
* @version 1.0
*
**/
public string function replaceSomeCharactersForPython(string strInput) {
var txtReturn = arguments.strInput;
// https://en.wikipedia.org/wiki/List_of_Unicode_characters
txtReturn = replaceNoCase(txtReturn, 'ä', 'ä', 'all');
txtReturn = replaceNoCase(txtReturn, 'ë', 'ë', 'all');
txtReturn = replaceNoCase(txtReturn, 'ï', 'ï', 'all');
txtReturn = replaceNoCase(txtReturn, 'ö', 'ö', 'all');
txtReturn = replaceNoCase(txtReturn, 'ü', 'ü', 'all');
txtReturn = replaceNoCase(txtReturn, 'à', 'à', 'all');
txtReturn = replaceNoCase(txtReturn, 'è', 'è', 'all');
txtReturn = replaceNoCase(txtReturn, 'ì', 'ì', 'all');
txtReturn = replaceNoCase(txtReturn, 'ò', 'ò', 'all');
txtReturn = replaceNoCase(txtReturn, 'ù', 'ù', 'all');
txtReturn = replaceNoCase(txtReturn, 'á', 'á', 'all');
txtReturn = replaceNoCase(txtReturn, 'é', 'é', 'all');
txtReturn = replaceNoCase(txtReturn, 'í', 'í', 'all');
txtReturn = replaceNoCase(txtReturn, 'ó', 'ó', 'all');
txtReturn = replaceNoCase(txtReturn, 'ú', 'ú', 'all');
txtReturn = replaceNoCase(txtReturn, 'ä', '\u00E4', 'all');
txtReturn = replaceNoCase(txtReturn, 'ë', '\u00EB', 'all');
txtReturn = replaceNoCase(txtReturn, 'ï', '\u00F6', 'all');
txtReturn = replaceNoCase(txtReturn, 'ö', '\u00FC', 'all');
txtReturn = replaceNoCase(txtReturn, 'ü', '\u00FC', 'all');
txtReturn = replaceNoCase(txtReturn, 'à', '\u00E0', 'all');
txtReturn = replaceNoCase(txtReturn, 'è', '\u00E8', 'all');
txtReturn = replaceNoCase(txtReturn, 'ì', '\u00EC', 'all');
txtReturn = replaceNoCase(txtReturn, 'ò', '\u00F2', 'all');
txtReturn = replaceNoCase(txtReturn, 'ù', '\u00F9', 'all');
txtReturn = replaceNoCase(txtReturn, 'á', '\u00E1', 'all');
txtReturn = replaceNoCase(txtReturn, 'é', '\u00E9', 'all');
txtReturn = replaceNoCase(txtReturn, 'í', '\u00ED', 'all');
txtReturn = replaceNoCase(txtReturn, 'ó', '\u00F3', 'all');
txtReturn = replaceNoCase(txtReturn, 'ú', '\u00FA', 'all');
txtReturn = replaceNoCase(txtReturn, "'", "\u0027", "all");
return txtReturn;
}
/**
*
* @hint just to get started;
*
* @comment: --
*
* @version --
*
**/
public any function testWithText(struct dataSet={}) {
// settingup variables for all kind of files to use temporary
var dynamicString = dateFormat(now(),'yyyymmdd')&timeFormat(now(),'HHmmss');
var fileName = 'testWithText_#dynamicString#.py';
var pythonFile = variables.pythonFilePath&"\"&fileName;
var batFileName = 'testWithText_#dynamicString#.bat';
var batFile = variables.pythonPatchPath&"\"&batFileName;
var wordFileName = 'testWithText.docx';
var wordFile = variables.wordSavedFilePath&"\"&wordFileName;
var wordFileInPython = pythonPathNotation(strInput=wordFile);
var orientation = wordDocOrientation(strInput='portrait');
/* This is all python code, so don't touch anything below */
var strFile = OverallPythonStart(orientationStruct=orientation);
strFile &= deleteParagraph();
// START: creating the document (.py-file, .bat-file and result: .doc(x)-file.
// table
strFile &= "table = document.add_table(rows=0, cols=1)"&Chr(13);
strFile &= "table.style = 'Table Grid'"&Chr(13);
strFile &= Chr(13);
var newCell = 'row_cells[0]';
strFile &= "row_cells = table.add_row().cells"&Chr(13);
strFile &= "delete_paragraph(#newCell#.paragraphs[0])"&Chr(13);
strFile &= Chr(13);
/* you can use a logo(s) or image(s) within the document
-- strFile &= genPythonImage(imagePath=logo, docObject=newCell, width=15, measureUnit='Mm');
--------------------------------------------------------------------------------------------- */
strFile &= genPythonDesciption(txtString='hier some text input', docObject=newCell);
strFile &= Chr(13);
// footer
strFile &= genPythonFooter(txtString='This is a footer-text');
// save this as a word document
strFile &= "document.save('#wordFileInPython#')" & Chr(13);
// END: creating the document.
var returnString = overallPythonEnd(strFile, batFile, pythonFile, wordFile);
return returnString;
}
}
All the way down is an example how to use it…
Function called: testWithText
Thanks all.
@Zackster I updated the debug, much better, THANKS! ![]()
@Rene_van_Wingerden Python is not my thing, I wish it was.
I’ve spent most of today trying to get my Word doc to format correctly, adding dash bullet points and correct spacing between lines and it’s been nothing but errors most of the way.
I am going to have a go at using Docx4j
I’ve managed to get DOCX4J working, but it was not easy trying to get the right JARS in place, I ended adding the lot from the bundle and will remove each one until it breaks.
The problem I have is that I can not control the DOCX margin sizes, it gives an error Error loading PgMar class: cannot load class through its string name, because no definition for the class with the specified name [org.docx4j.wml.PgMar] could be found caused by (java.lang.ClassNotFoundException:org.docx4j.wml.PgMar not found by lucee.core [48];java.lang.ClassNotFoundException:org.docx4j.wml.PgMar;java.lang.ClassNotFoundException:org.docx4j.wml.PgMar;)
There is no WML in the JAR, and I can not find one in the repository.
I’m wondering if anybody in here has managed to get this working with Lucee, or has another approach that will do the job?
Thanks
Have you considered .CSV? If importing into Word is what you’re after there isn’t really much point in docx.
Just a thought.
Hi @ian_hickey unfortunately I need it in Word, with some control over the formatting and I need to fully automate the creation of the Word doc
I should also add that there is a WML folder, but it was in a different file than expected and not containing all of the required classes, I suspect I am using the wrong ones, I’m trying to find detailed documentation.
I’ve managed to get to add dash bullet points, add paragraphs identical to as if I pressed ENTER in Word, and change spacing so there is no spacing above or below the cursor on each line.
However, I have hit a wall controlling the page margins, inserting a solid full width bar, adding text with a hyperlink and also fixing the issue of the document opening in compatibility mode.
docx4j-helloworld.cfm (6.3 KB)
A post was split to a new topic: How to use poi-it in Lucee
I opted to employ the help for somebody that has a higher skill set than myself who has worked with docx4j in the past. I also have a post in the docx4j where I was pointed to a builder you can use, you upload a word doc and it gives to requirements to replicate the document.
I will report back when this is resolved and share the code
I have managed to get docx4J working and created the exact DOCX that I need, and when I see I, I mean a developer I hired who is much better than me. Once I get the clear instructions for integration of the JAR as in which is need, which is not, as I dumped a lot in and I don’t think I need them all, I will share the info here.
My CFM is very specific to my needs and data, but I will create a CFM that gives some pointers to use the controls that I am using, page breaks, paragraph control, page margin etc. I have to also admit I also got some help from cursor which I have found to work really well…until it doesn’t, when it goes wrong, it goes WRONG!
On another note, I also need to create a PDF that looks like the DOCX. Is anybody familiar with any way to create PDF’s from data, short of creating a HTML page and converting that to a PDF? docx4j has the ability I believe if you have the enterprise, but it’s too expensive at about $1,500 a year, or close to $5k for perpetual license.
I had also consider I could create a DOCX then convert that to PDF with the right plug in, although there are times I don’t need the DOCX, but I do need them to look the same.
Thanks
Last time you spoke of using Windows, why not just print the docx file to pdf?
Install LibreOffice, its open source.
then set the path of the file you need converted, the path of where the binary for LibreOffice is and the path where you out the output file
you can then do something like this:
#pathtoLibreOffice#" arguments='--headless --convert-to pdf --outdir "#OutputPath#" "#inputPath#"'
Now you tell me! ![]()
I’ve almost got it perfected using HTML → PDF. I’m not familiar with LibreOffice, so I can literally use Lucee to reference the DOCX and have a perfect PDF conversion.
My current solution has taken quite a bit of work, weird things like an 11pt font is not the same in the PDF if I set it to 11pt, some font, it’s larger, so lots of messing around to get a perfect replication.
That might be a better solution if I only have to think about getting the DOCX perfected and the PDF is fire and forget, although on saying that it would force me to have to create a DOCX all the time when I might only need a PDF, but it’s likely not a massive issue.